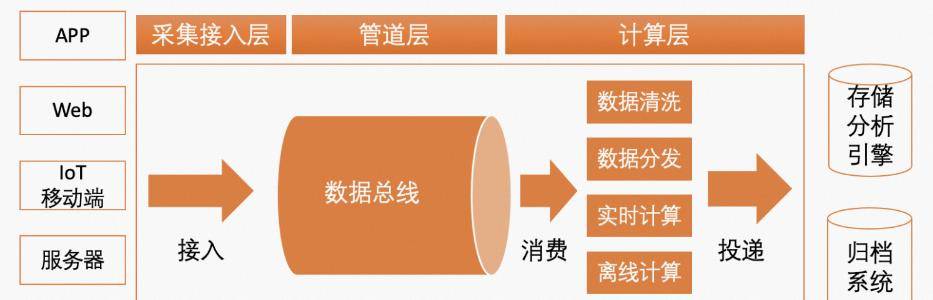
介绍:数据总线作为大数据架构中的流量中枢,在各个大数据组件之间起着数据桥梁的作用。.服务器、K8、App、Web、物联网/移动终端等产生的各种异构数据,可以通过数据总线进行实时访问。可以进行统一的数据管理,实现与上级系统的分离;然后可以异步实现数据清洗、数据分发、实时计算、离线计算等计算过程,然后将结构化数据传递给下游分析和归档系统,达到构建清晰数据流的目的。广义上包括数据采集与访问、传输线路、数据存储队列、消费计算、交付等。所有的。
本文由阿里云SLS的徐克佳撰写
GIAC2022全球互联网架构大会上海
共享时的主题内容。
云原生场景下的数据总线需求场景及挑战
数据总线介绍
作为大数据架构中的传输节点,数据总线充当各种大数据组件之间的数据桥梁。服务器、K8、APP、Web、物联网/移动终端等产生的各种异构数据,可以通过数据总线进行实时访问。可以进行统一的数据管理,实现与上级系统的分离;然后可以异步实现数据清洗、数据分发、实时计算、离线计算等计算过程,然后将结构化数据传递给下游分析和归档系统,达到构建清晰数据流的目的。广义上包括数据采集与访问、传输线路、数据存储队列、消费计算、交付等。
所有的。
通过数据总线可以轻松实现以下目标:
生产者与消费者分离:消费者不需要感知作者的任何细节,从而降低了对接系统的复杂度,增加了系统的可靠性。
应对流量高峰,数据生产与数据消费异步,消峰填谷。
定义统一的格式和操作语义:访问不同的异构数据,通过数据处理创建统一的格式。
我举一个简单的例子,在广告搜索计算系统中,广告点击数据非常重要。部分点数据往往被多方订阅和消费,应用场景各不相同。有二阶精度的实时计算服务,也有每小时或每天的类Hadoop批处理作业。如果数据直接联动,需要考虑各种异常场景,使得系统异常复杂。通过数据总线,可以显着降低系统的复杂度,提高系统的可靠性。这可以确保任何数据收集系统在重新上线时都可以从之前的断点继续处理数据,即使它经历了离线维护或中断。处理。云原生场景的技术挑战
面对每天百亿级的读写,近百PB的数据流量,数以万计的用户,构建高可用的数据总线将是一个非常具有挑战性的任务。以下是某些场景的交通场景的简短列表:
制作人:由于商家宣传等活动,几分钟内流量增加了十倍、百倍;
消费者:有几十个订阅者同时消费某种数据;
每天,以不同方式访问数百个异构数据源,需要进行大量操作。
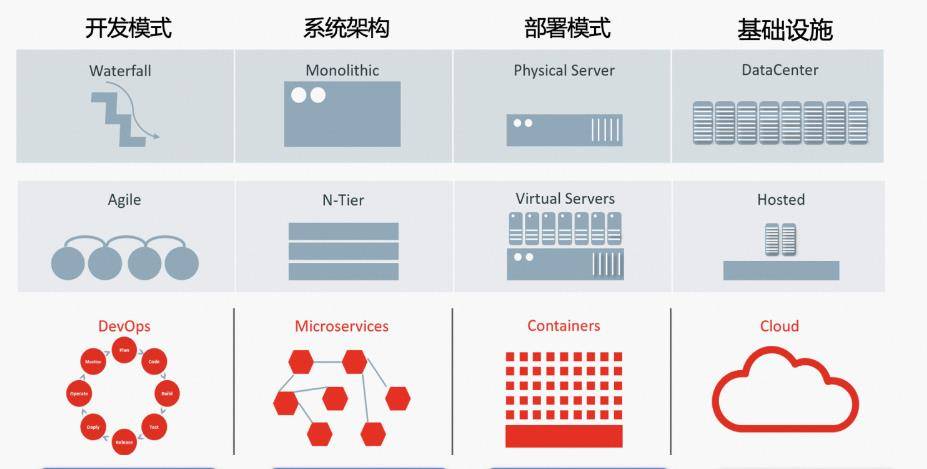
经过几十年的快速发展,整个开发模式、系统架构、部署模式、基础架构都发生了数次革命性的变化,带来了更快的开发和部署效率。然而,整个系统和网络环境变得更加复杂,部署方式和运行环境变得更加动态和不确定,数据源的数量和数据量显着增加,流量波动等不确定因素增加。增加了原有结构的难度和差异。这些都是云时代给数据总线带来的新要求。
综上所述,云原生时代数据总线的技术挑战可以从采集访问层、流水线层、计算层三个方面展开。采集与接入层侧重于数据源的丰富接入、接入的易用性、资源开销、数据采集的可靠性;管道层关注网络质量、带宽和可扩展性、安全性和隔离性、环境财富等;计算层侧重于计算语法能力、流量处理带宽和可扩展性。
开源方案的选择与比较
目前业界大数据的主流架构大致可以分为五部分,其中前三部分构成了数据总线。
采集端:承载可观测数据采集和数据处理前的一些功能。随着云原生的发展,端集也需要顺应时代潮流,提供
友好支持K8s合集。常见的采集终端包括Filebeat、FluentD/Fluent-bIt、Telegraf和我们开源的iLogtAIl。

消息队列:集合
Agent往往不会将采集到的数据直接发送到存储系统,而是写入消息队列,起到削峰填谷的作用,避免流量泛洪导致存储系统宕机。常见的消息队列有Kafka、RabbitMQ等。
计算:用于消费消息队列中的数据,经过处理聚合后输出到存储系统。最常见的有Flink、Logstash等。值得注意的是,一些公司也开始部署开源版本的iLogtail作为协议架构中的计算层。
StorageandAnalysisTool:提供采集数据进行持久化存储的能力,提供查询分析能力。常见的存储分析工具有
Elasticsearch、ClickHouse、Loki和Prometheus时序、influxdb等。
可视化:p
Kibana和Grafana提供了可视化收集数据的选项。
用户可以使用采集端、消息队列和计算提供的上述开源组件创建数据总线。虽然基于开源组件构建数据总线在技术上是可行的,但整体实现复杂度较高,需要维护多个系统进行协调。此外,也无法完全应对上述云原生场景所面临的技术挑战。一个不可逾越的差距是,例如,网络质量和区域规划。
整体数据总线架构
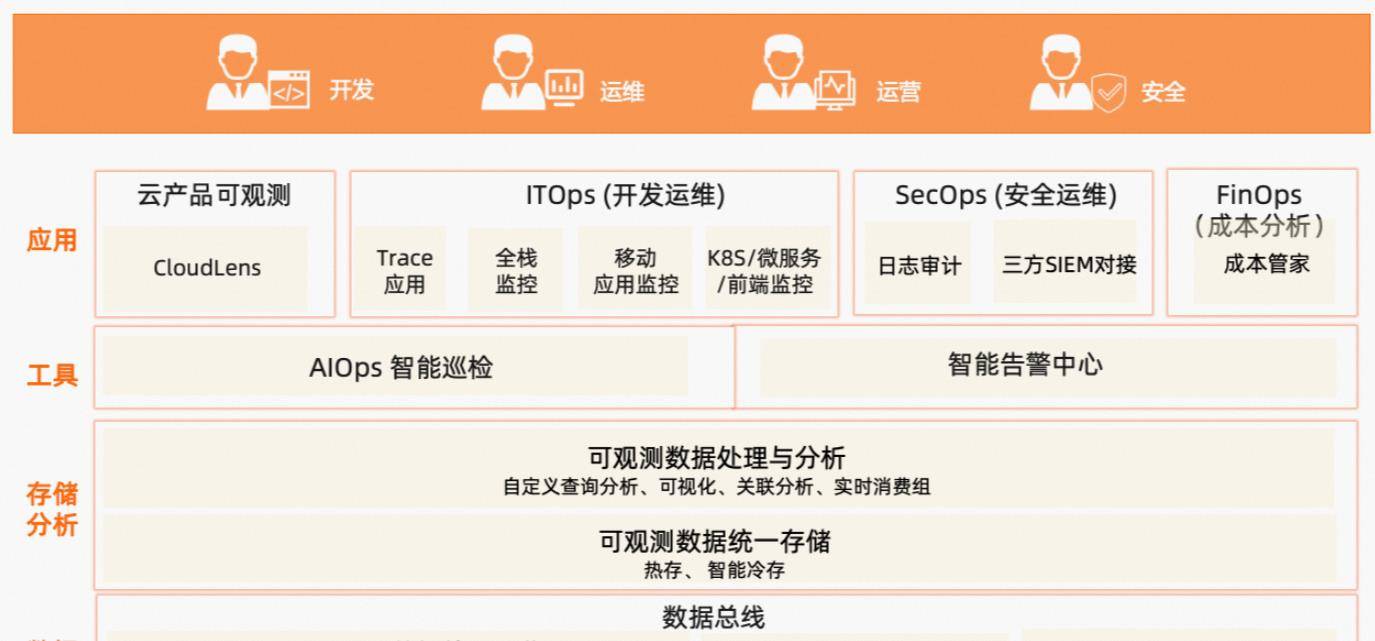
一个可观察的平台不仅要解决数据的获取和查询问题,还要提供针对特定业务场景的应用能力,帮助客户从碎片化、低信息化的数据中获取更多的数据价值。

典型的云原生可观察平台自下而上分为四层:数据总线、存储分析、工具和应用。其中,数据总线是整个可观察平台的数据基础,为数据分析和更高层次的业务应用提供数据保障。正因为数据总线足够基础,必须足够可靠和稳定,才能保证业务数字化过程中数据的畅通,能够灵活应对运营变化的需求。接下来重点分享阿里云SLS数据总线的架构和实践。
在本文的第一部分,我们设想了一个典型的数据总线可以分为三层:采集访问层、流水线层和计算层。同理,可以划分对应的SLS数据总线架构。
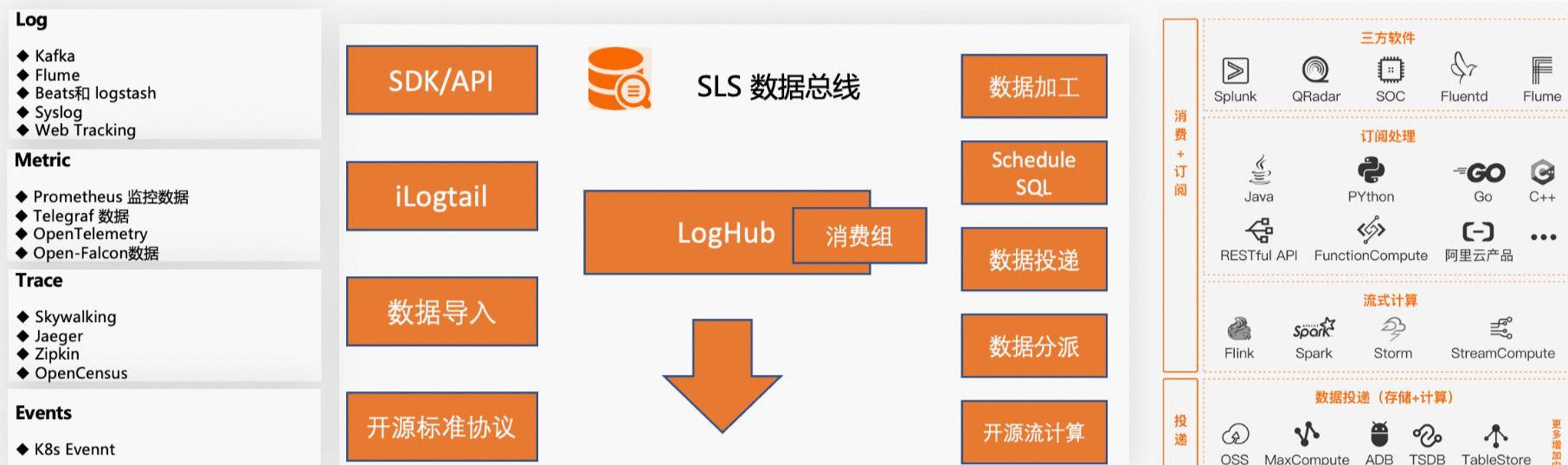
采集接入层:承载对数据总线上所有数据的接入(支持Log、Metric、Trace、Event等),与阿里云服务深度集成。接入方式基于一个SDK/API扩展了各种接入方式,如端部的iLogtail可观察收集器、数据导入服务、标准开源协议等。
管道层:LogHub作为数据总线的主要流量节点,其功能完全可以替代Kafka。通过RestfulAPI对外提供访问服务,通过消费组提供实时消费服务。
计算层:作为LogHub的下游服务,基于实时消费群体,提供各种数据处理和交付服务;并在生态上支持主流开源流计算的对接。
以上,我们已经对SLS数据总线有了大致的了解,接下来我们将从数据接入、运营中心、数据处理三个维度进行详细介绍。数据访问技术架构与实践
数据访问选项概述
LogHub作为数据总线的主要枢纽,默认提供HTTP/HTTPSAPI编写。同时还提供多种语言的SDK,简化接入场景,增加可靠性。SDK涵盖JAVA、Go、C++等服务端应用,Android、IOS等移动端场景,甚至JavaScript等前端场景。
自主研发的开源可观察数据采集器iLogtail,承载了跨windows、linux、X86、ARM架构的服务器场景和容器场景可观察数据采集能力。借助阿里云的优势,无缝支持阿里云上各种常见云服务的日志、指标和安全审计数据的采集。
对常用协议也有丰富的支持,兼容Syslog、Kafka、Promethous、JDBC、OpenTelemertry等开源协议;支持Logstash、Fluentd、Telegraf等多种开源采集工具。
制作人图书馆
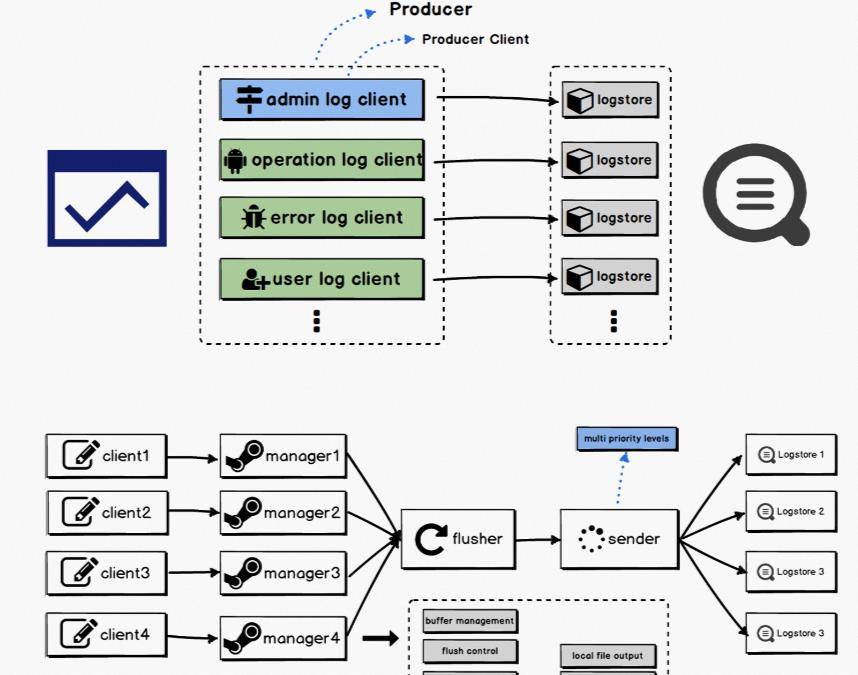
针对Java、Go等大数据、高并发场景,我们提供基于SDK的JavaProducer和GoProducer;对于物联网/嵌入式设备,我们运行CProducer。
相较于直接通过API或SDK发送数据,Producer提供了更高级别的封装,极大地提升了性能和可靠性。
线程安全:Producer中所有的方法和暴露的接口都是线程安全的。
异步调度:客户端计算与I/O逻辑分离。调用Producer发送接口通常会立即返回,Producer会在内部存储合并发送的数据,然后分批发送,以提高吞吐量。
失败重试:对于可重试的异常,Producer会根据用户配置的最大重试次数和重试下载时间进行重试。
Gracefulshutdown:当用户调用shutdown方法关闭时,Producer发送所有缓存的数据,防止日志丢失。
高性能:通过多线程、缓冲策略、批量发送等手段,有效提高发送效率。
iLogtail可观察数据收集器
iLogtail是数据总线访问的重要流量来源。具有重量轻、性能高、配置自动化等生产级特点。可以部署在物理机、虚拟机、Kube.NETes等不同环境中,采集遥测数据。
iLogtail的核心定位是可观察数据采集器,帮助开发者构建统一的数据采集层,帮助可观察平台打造各种更高层次的应用场景。通过iLogtail可以很好的解决数据总线数据的访问问题。
凭借阿里巴巴/蚂蚁集团的持续训练和公有云场景,相比开源代理(如Fluentd、Logstash、Beats),iLogtail在性能、资源消耗、可靠性、多租户隔离等硬指标上具有优势。和K8s支持,可满足各种业务场景的严苛要求。目前,iLogtail已于2022年6月29日全面开源,吸引了众多开发者的关注,2022年11月7日Githubstar数也突破1K。
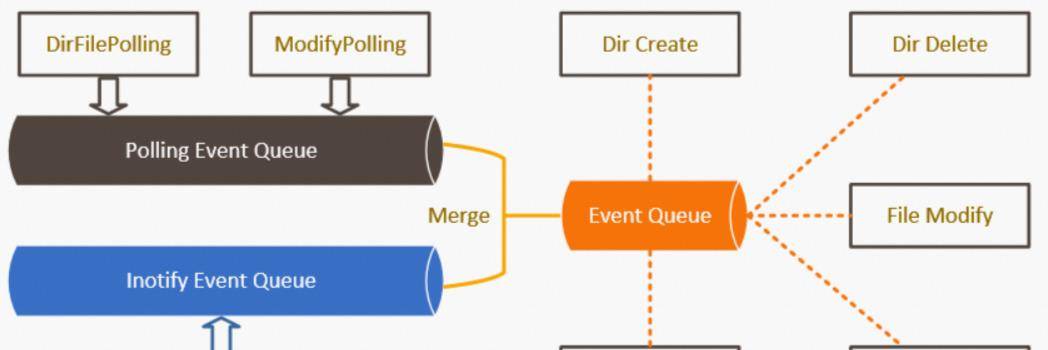
高性能和低开销是iLogtail的主要优势之一。iLogtail使用inotify作为Linux下文件监控的主要手段,提供毫秒级延迟的数据发现能力。同时,考虑到不同的操作系统,支持不同的特殊采集场景,iLogtail还采用了轮询作为数据发现方式。使用轮询和事件的混合方法,iLogtail创建了一种兼具性能和健壮性优势的文件发现机制。另外,iLogtail使用了非锁定的事件处理模型。不同于业界其他开源代理每次配置分配独立的线程/goroutine读取数据,iLogtail数据只配置一个线程读取。
由于数据读取的瓶颈不是计算机而是磁盘,所以一个线程足以完成配置事件和数据读取的整个处理。使用单线程可以让iLogtail中的事件处理和数据读取发生在无锁的环境中,数据结构更轻量,相比多线程处理具有更好的性价比。
在生产环境中,一个服务有上百个采集配置是很正常的。每个配置的优先级、日志生成速率、处理方式、上传目的地址可能会有所不同。因此,需要有效解决如何隔离不同的适配。确保采集配置的QoS不受某些配置异常影响的配置。iLogtail利用基于时间片的收获调度、多级高低水反馈队列、非阻塞事件处理、流量控制/关闭策略、动态配置更新等多项关键技术,并将其集成实现隔离,公平性和可靠性。具有五个特点的多租户绝缘解决方案:可控性和成本效益。经过双十一流量高峰期的多年考验,该方案相较于其他开源方案具有更高的稳定性和性价比优势。
毫不夸张的说,数据源的多样性可以说是数据总线的生命线,否则聪明女人难做无米之炊。iLogtail通过插件化设计,超越简单的文件采集,有效拓展上下游生态,让iLogtail成为真正的可观察采集器。
目前,iLogtail已经支持访问很多数据源。数据源类型包括Log、Metric和Trace。数据源除了文件采集,还包括对HTTP、MySQLBinlog、Prometheus、Skywalking、Syslog等标准协议的支持;iLogtail还支持eBPF,实现非侵入式网络数据采集功能。数据输出的生态逐渐从SLS扩展到Kafka、gPRC等。未来还将通过开源社区支持ClickHouse、ElasticSearch等。
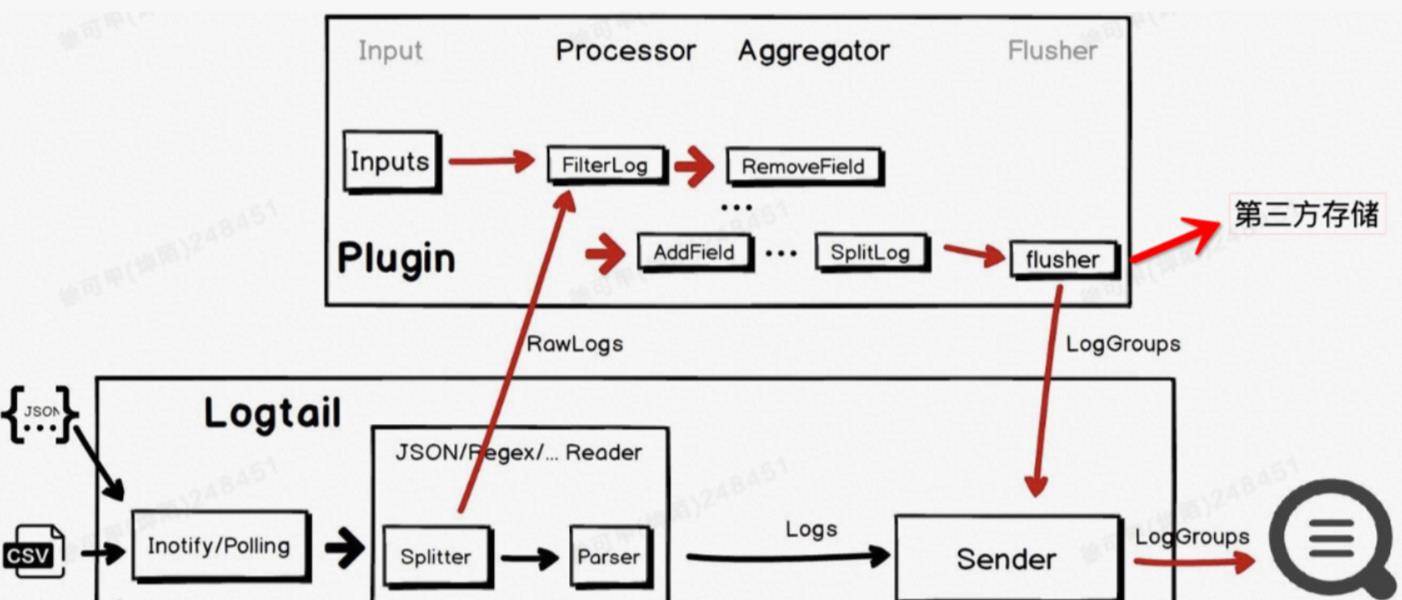
面对众多异构数据的访问,数据总线的职责之一就是通过数据处理创建统一的数据格式。iLogtail还提供了强大的数据处理能力,可以提前完成数据格式正则化、数据过滤、上下文赋值等工作。iLogtail整体采用PipeLine设计。首先,数据通过Input插件采集,经过采集配置中设置的处理器处理,打包到Aggregator插件中,最后通过Flusher发送到存储系统。数据处理环境包括数据切分、字段提取、过滤、数据增强等。所有插件模块都可以根据需要进行组合。
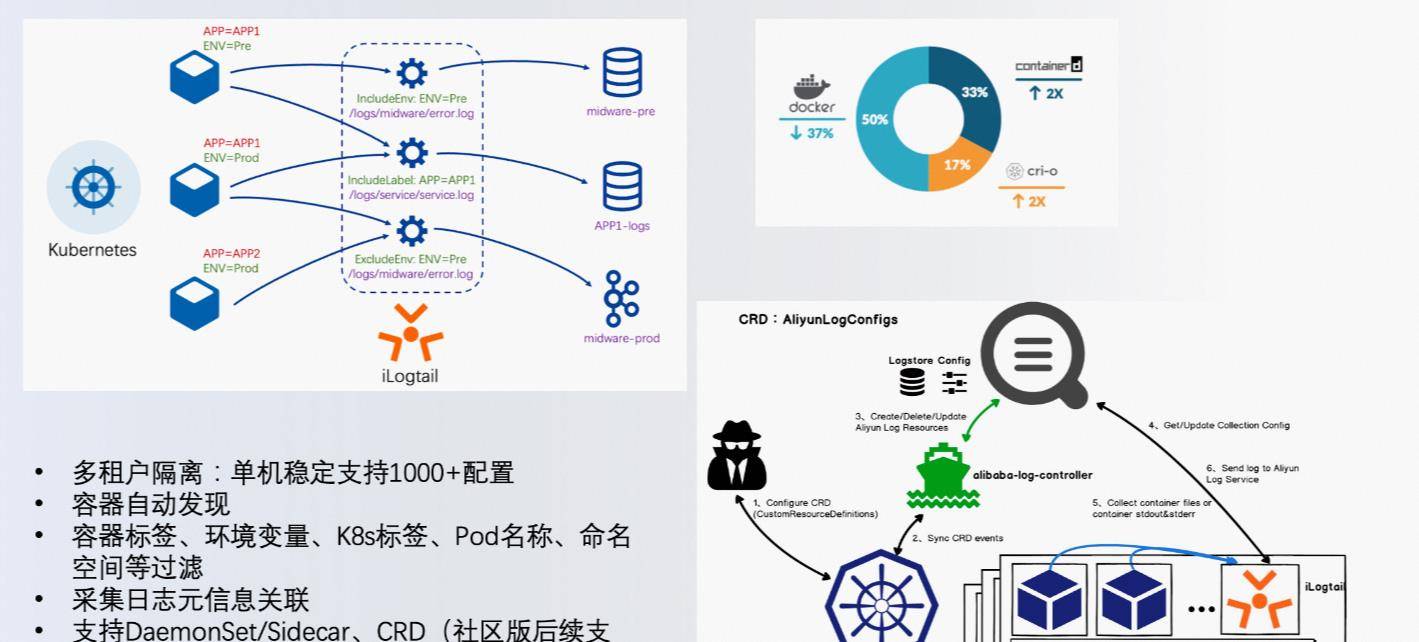
Logtail原生云实现,全面支持Kubernetes,目前支持两种常见的容器运行时Docker和Containerd。
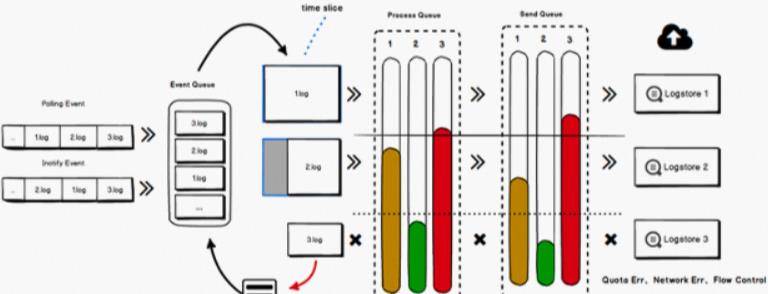
iLogtail通过实时监控容器列表,维护容器和日志采集路径映射,结合高效的文件采集能力,提供极致的容器数据采集体验。
iLogtail支持容器标签、环境变量、K8s标签、Pod名称、命名空间等多种方式进行容器筛选,为用户配置采集资源提供便捷的选择。支持DaemonSet、Sidecar、CRD等多种部署方式,针对不同的使用场景提供灵活的部署选择。此外,对于对CICD的自动化部署和运维要求较高的用户,iLogtail提供了原生的K8支持,支持通过CRD进行采集和配置管理。在该方案中,iLogtailK8s增加了一个名为AliyunLogConfig的CustomResourceDefinition扩展。同时开发了alibaba-log-controller,用于监控AliyunLogConfig事件,自动创建iLogtail采集配置,完成日志采集。
交通中心技术架构与实践
LogHub作为SLS数据总线传输枢纽,是一个高性能的数据管道,支持海量可观察数据的实时访问和消费。在可观察的数据场景中,可以使用像Kafka这样的消息队列产品,在性能、易用性和稳定性上都更好。
LogHub可以理解为一个connection-only的日志队列结构,通过多个shard的组合实现水平IO和存储扩展。并在队列的基础上创建多层索引,可以快速找到每条数据在队列中的位置,为队列模型配备随机查询能力。
弹性:支持1~512个分区(Shard),毫秒级扩缩容。
高吞吐量:一个分片支持5MB/s的写入和10MB/s的读取。
容错性高:单独故障转移不影响正常写入。
去重:支持写ExtractlyOnce去重。
随机查询:1%的额外存储开销,支持任意数据的随机搜索(1IO)。
点击查看原文,获取更多福利!
版权声明:本文内容由阿里云实名注册用户创作,版权归原作者所有。阿里云开发者社区不拥有自己的版权,也不承担相应的法律责任。具体规则可以在《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》找到。如果您发现本社区涉嫌抄袭,请填写版权投诉表并举报。一经查实,本社区将立即删除涉嫌侵权的内容。