
数据可视化可深入了解数据集中变量之间的分布和关系。
此洞察力有助于选择在建模之前应用的数据准备以及最适合数据的算法类型。
Seaborn 是 Python 的数据可视化库,它在流行的 Matplotlib 数据可视化库之上运行,并且提供了简单的界面和美观的图形。

本文对机器学习中的 Seaborn 数据可视化作了简要介绍。
看完本文,你将知道:
- 如何使用条形图,直方图以及箱形图来总结变量的分布。
- 如何使用线图和散点图总结关系。
- 如何比较同一图上不同类别值的变量的分布和关系。
概述
本教程分为六个部分:
- Seaborn数据可视化库
- 线图
- 条形图
- 直方图
- 箱形图
- 散点图
Seaborn数据可视化库
Python 的主要绘图库称为 Matplotlib 。
Seaborn 是一个绘图库,它不仅提供了一个更简单的界面,为机器学习所需的绘图提供了合理的默认值,而且最重要的是,这些绘图在外观上比 Matplotlib 更好。
Seaborn 要求首先安装 Matplotlib。
我们可以使用 pip 直接安装 Matplotlib ,如下所示:
sudo pip install matplotlib
安装后,可以通过输出版本号来确认可以加载和使用该库,如下所示:
# matplotlib
import matplotlib
print('matplotlib: %s' % matplotlib.__version__)
我们可以得到 Matplotlib 库的当前版本。
matplotlib: 3.1.2
接下来,也可以使用 pip 安装 Seaborn 库:
sudo pip install seaborn
安装好后,我们还可以通过打印版本号来确认可以加载和使用该库,如下所示:
# seaborn
import seaborn
print('seaborn: %s' % seaborn.__version__)
运行示例将打印Seaborn库的当前版本。
seaborn: 0.10.0
要创建 Seaborn 可视化图形,必须导入 Seaborn 库并调用函数来创建图。
重要的是,Seaborn 绘图功能希望将数据作为 Pandas 数据帧提供。这意味着,如果你要从CSV文件加载数据,则必须使用 read_csv()之类的 Pandas 函数将数据作为数据帧加载。绘制时,可以通过数据帧名称或列索引指定列。
要显示该图,可以在 Matplotlib 库上调用 show()函数。
...
# 显示图表
pyplot.show()
或者,可以将图保存到文件,例如 PNG 格式的图像文件。savefig()函数 Matplotlib 可用于保存图像。
...
# 保存图表
pyplot.savefig('my_image.png')
现在我们已经安装好 Seaborn 了,让我们看一下使用机器学习数据时可能需要的一些常见可视化图表。
线图
我们一般使用线图来呈现定期收集的数据观察结果。
x 轴表示规则间隔,例如时间。y 轴显示观测值,按 x 轴排序并通过一条线连接。
可以通过调用 lineplot()函数并在常规间隔中传递 x 轴数据和观察值的 y 轴来在 Seaborn 中创建线图。
我们可以使用每月汽车销售的时间序列数据集来演示折线图。
Github数据集链接:https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv
数据集有两列:“ 月 ”和“ 销售”。月将用作 x 轴,销售量将绘制在 y 轴上。
...
# 创建线图
lineplot(x='Month', y='Sales', data=dataset)
完整示例如下:
#时间序列数据集的线图
from pandas import read_csv
from seaborn import lineplot
from matplotlib import pyplot
# 加载数据集
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv'
dataset = read_csv(url, header=0)
# 创建线图
lineplot(x='Month', y='Sales', data=dataset)
# 显示线图
pyplot.show()
首先运行示例将加载时间序列数据集并创建数据的折线图,以清楚地显示销售数据中的趋势和季节性。
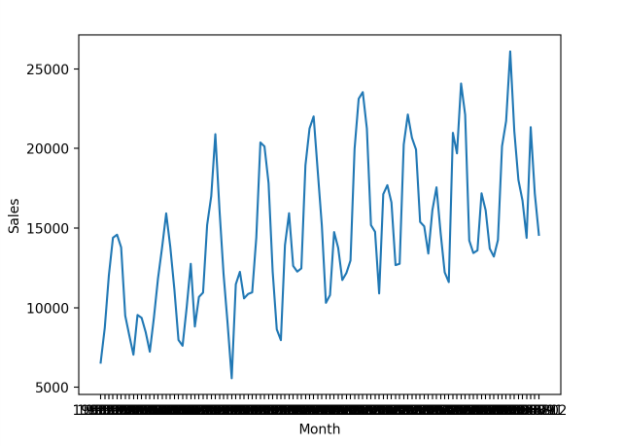
时间序列数据集的线图
条形图
条形图通常用于显示多个类别的相对数量。
x 轴代表均匀分布的类别。y 轴代表每种类别的数量,并以条形图从基线到 y 轴上的适当水平绘制。
可以通过调用 countplot()函数并传递数据来在 Seaborn 中创建条形图。
我们将展示条形图,其中包含来自乳腺癌分类数据集的变量,该变量由分类输入变量组成。
乳腺癌分类数据集链接:https://raw.githubusercontent.com/jbrownlee/Datasets/master/breast-cancer.csv
我们只绘制一个变量,在这种情况下,第一个变量是年龄段。
...
# 创建线图
countplot(x=0, data=dataset)
完整示例代码如下:
#分类变量的条形图
from pandas import read_csv
from seaborn import countplot
from matplotlib import pyplot
#加载数据集
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/breast-cancer.csv'
dataset = read_csv(url, header=None)
# 创建条形图
countplot(x=0, data=dataset)
# 显示条形图
pyplot.show()
首先运行示例将加载乳腺癌数据集并创建数据的条形图,以显示每个年龄组以及可及范围内的个体(样本)数量。
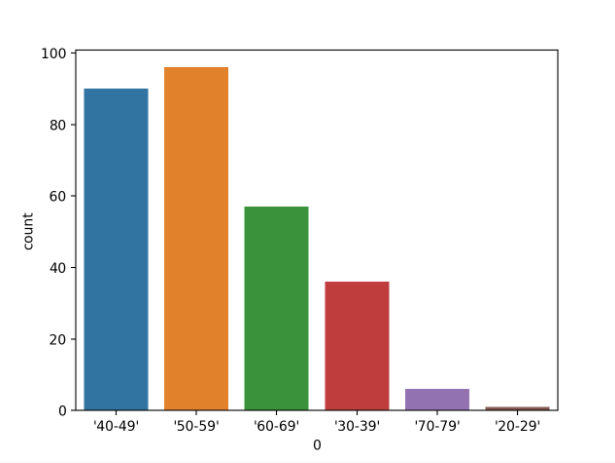
年龄范围分类变量的条形图
此外,如果我们还想针对类标签绘制变量(例如第一个变量)的每个类别的计数。
可以通过使用 countplot()函数并通过“ hue ”参数指定类变量来实现,如下所示:
...
# 创建条形图
countplot(x=0, hue=9, data=dataset)
完整示例代码如下:
# 分类变量与类变量的条形图
from pandas import read_csv
from seaborn import countplot
from matplotlib import pyplot
# 加载数据集
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/breast-cancer.csv'
dataset = read_csv(url, header=None)
# 创建条形图
countplot(x=0, hue=9, data=dataset)
# 显示条形图
pyplot.show()
首先运行示例将加载乳腺癌数据集,并创建数据的条形图,以显示每个年龄组以及属于每个组的个体(样本)数量(由数据集的两个类别标签分隔)。
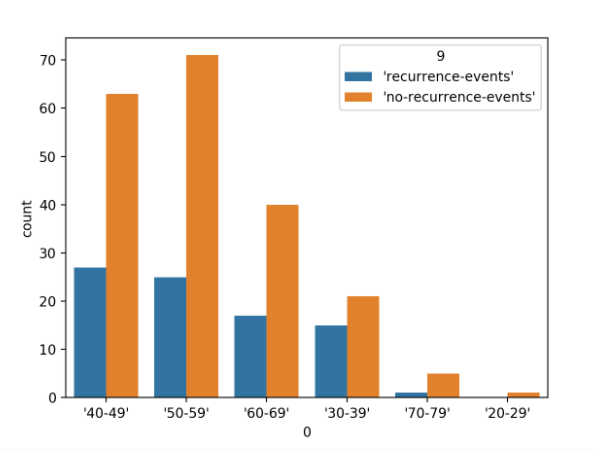
按类别标签划分的年龄范围分类变量的条形图
直方图
直方图通常用于总结数值数据样本的分布。
x 轴表示观测值的离散区间或间隔。例如,值介于 1 到 10 之间的观测值可以分为五个 bin,值 [1,2] 将分配给第一个 bin,[3,4] 将分配给第二个 bin,依此类推。
y 轴表示数据集中属于每个 bin 的观测值的频率或计数。
本质上,数据样本被转换为条形图,其中 x 轴上的每个类别都代表观察值的间隔。
可以通过调用 distplot()函数并传递变量来在 Seaborn 中创建直方图。
我们将展示一个带有糖尿病分类数据集中数值变量的箱线图。我们只绘制一个变量,在这种情况下,是第一个变量,即患者怀孕的次数。
糖尿病分类数据集:https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv
...
# 创建直方图
distplot(dataset[[0]])
完整示例代码如下:
# 数值变量的直方图
from pandas import read_csv
from seaborn import distplot
from matplotlib import pyplot
# 加载数据集
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv'
dataset = read_csv(url, header=None)
# 创建直方图
distplot(dataset[[0]])
# 显示直方图
pyplot.show()
首先运行示例将加载糖尿病数据集并创建变量的直方图,以硬截止值为零的形式显示值的分布。
该图显示了直方图(bin的数量)以及概率密度函数的平滑估计。
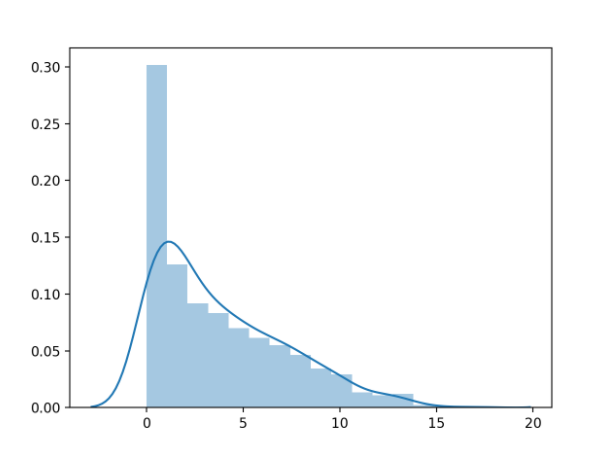
怀孕次数直方图
箱形图
通常使用箱形图来概括数据样本的分布。
x 轴用于表示数据样本,如果需要,可以在 x 轴上并排绘制多个箱形图。
y 轴表示观测值。绘制一个方框来汇总数据集中的中间 50%数据,从观察值的第 25 个百分位数开始,到第 75 个百分位数为止。这称为四分位间距或 IQR。用一条线绘制中位数或第 50 个百分位数。
从盒子的两端开始绘制称为须状的线,计算公式为(1.5 * IQR),以显示分布中合理值的预期范围。晶须外的观测值可能是异常值,并用小圆圈绘制。
可以通过调用 boxplot()函数并传递数据来在 Seaborn 中创建一个箱线图。
我们将展示一个带有糖尿病分类数据集中数值变量的箱线图。我们只绘制一个变量,在这种情况下,是第一个变量,即患者怀孕的次数。
...
# 创建箱形图
boxplot(x=0, data=dataset)
完整示例代码如下:
# 数值变量的箱型图
from pandas import read_csv
from seaborn import boxplot
from matplotlib import pyplot
# 加载数据集
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv'
dataset = read_csv(url, header=None)
# 创建箱形图
boxplot(x=0, data=dataset)
# 显示箱形图
pyplot.show()
首先运行示例,加载糖尿病数据集,并创建第一个输入变量的箱形图,以显示患者怀孕次数的分布。
我们可以看到中位数略高于2.5倍,一些离群值上升了15倍左右。
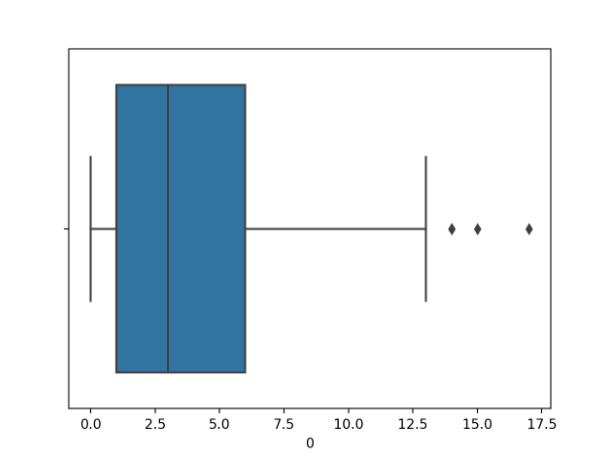
怀孕次数箱形图
此外,如果我们还想针对类别标签针对类别变量(例如第一个变量)的每个值绘制数字变量的分布。
可以通过调用 boxplot()函数并将 class 变量作为 x 轴和数值变量作为 y 轴来实现。
...
# 创建箱形图
boxplot(x=8, y=0, data=dataset)
完整示例代码如下:
#数值变量与类标签的箱形图
from pandas import read_csv
from seaborn import boxplot
from matplotlib import pyplot
# 加载数据集
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv'
dataset = read_csv(url, header=None)
# 创建箱形图
boxplot(x=8, y=0, data=dataset)
# 显示箱形图
pyplot.show()
首先运行示例将加载糖尿病数据集并创建数据的箱形图,将怀孕次数的分布作为两个类标签的数值变量。
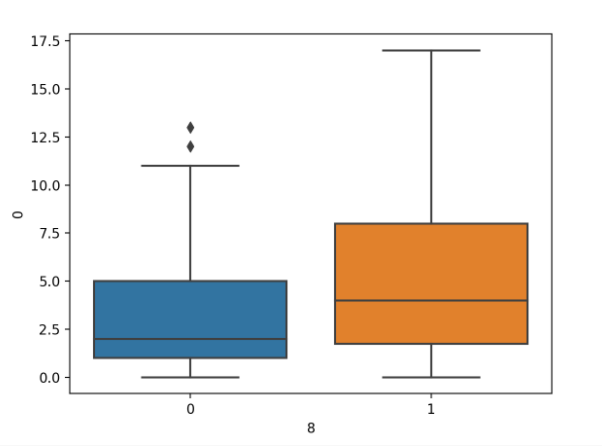
分类标签的怀孕次数箱形图
散点图
散点图或散点图通常用于总结两个配对数据样本之间的关系。
配对的数据样本意味着针对给定的观察记录了两个度量,例如一个人的体重和身高。
x 轴代表第一样品的观察值,y 轴代表第二样品的观察值。图上的每个点代表一个观察值。
可以通过调用 scatterplot()函数并传递两个数值变量来在 Seaborn 中创建散点图。
我们将展示一个散点图,其中包含来自糖尿病分类数据集的两个数值变量。我们将绘制第一个变量与第二个变量的关系图,在这种情况下,第一个变量是患者怀孕的次数,第二个变量是口服糖耐量测试两小时后的血浆葡萄糖浓度。
糖尿病分类数据集:https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv
...
# 创建散点图
scatterplot(x=0, y=1, data=dataset)
完整示例代码如下:
# 两个数值变量的散点图
from pandas import read_csv
from seaborn import scatterplot
from matplotlib import pyplot
#加载数据集
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv'
dataset = read_csv(url, header=None)
#创建散点图
scatterplot(x=0, y=1, data=dataset)
# 显示散点图
pyplot.show()
首先运行示例将加载糖尿病数据集并创建前两个输入变量的散点图。
我们可以看到两个变量之间的关系有些统一。
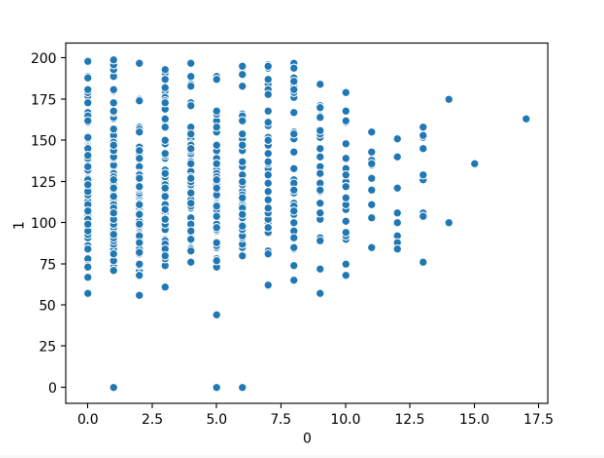
怀孕次数与血浆葡萄糖数值变量散点图
我们可能还想针对类标签绘制一对数字变量的关系。
这可以使用 scatterplot()函数并通过“ hue ”参数指定类变量来实现,如下所示:
...
# 创建散点图
scatterplot(x=0, y=1, hue=8, data=dataset)
完整示例代码如下:
# 两个数值变量与类标签的散点图
from pandas import read_csv
from seaborn import scatterplot
from matplotlib import pyplot
# 加载数据集
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv'
dataset = read_csv(url, header=None)
# 创建散点图
scatterplot(x=0, y=1, hue=8, data=dataset)
# 显示散点图
pyplot.show()
首先运行示例将加载糖尿病数据集,并创建前两个变量与类标签的散点图。
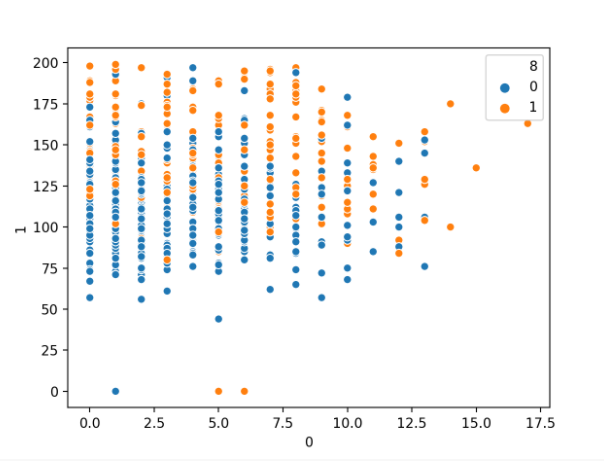
按类别标签划分的怀孕次数与血浆葡萄糖数值变量散点图













