import matplotlib.pyplot as plt
import osqp
import numpy as np
from scipy import sparse
import random
# 障碍物设置
obs = [[5, 10, 2, 3], [15, 20, -2, -0.5], [25, 30, 0, 1]] # start_s,end_s,l_low,l_up
s_len = 50
delta_s = 0.1
n = int(s_len / delta_s)
x = np.linspace(0, s_len, n)
up_bound = [0] * (5 * n + 3)
low_bound = [0] * (5 * n + 3)
s_ref = [0] * 3 * n
dddl_bound = 0.01
####################边界提取################
l_bound = 5
for i in range(n):
for j in range(len(obs)):
if x[i] >= obs[j][0] and x[i] <= obs[j][1]:
low_ = obs[j][2]
up_ = obs[j][3]
break
else:
up_ = l_bound
low_ = -l_bound
up_bound[i] = up_
low_bound[i] = low_
s_ref[i] = 0.5 * (up_ + low_)
for i in range(3 * n, 4 * n):
up_bound[i] = dddl_bound * delta_s * delta_s * delta_s / 6
low_bound[i] = -dddl_bound * delta_s * delta_s * delta_s / 6
for i in range(4 * n, 5 * n):
up_bound[i] = dddl_bound * delta_s * delta_s / 2
low_bound[i] = -dddl_bound * delta_s * delta_s / 2
####################构造P和Q################
w_l = 0.005
w_dl = 1
w_ddl = 1
w_dddl = 0.1
eye_n = np.identity(n)
zero_n = np.zeros((n, n))
P_zeros = zero_n
P_l = w_l * eye_n
P_dl = w_dl * eye_n
P_ddl = (w_ddl + 2 * w_dddl / delta_s / delta_s) * eye_n - 2 * w_dddl / delta_s / delta_s * np.eye(n, k=-1)
P_ddl[0][0] = w_ddl + w_dddl / delta_s / delta_s
P_ddl[n - 1][n - 1] = w_ddl + w_dddl / delta_s / delta_s
P = sparse.csc_matrix(np.block([
[P_l, P_zeros, P_zeros],
[P_zeros, P_dl, P_zeros],
[P_zeros, P_zeros, P_ddl]
]))
q = np.array([-w_l * s_ for s_ in s_ref])
####################构造A和LU################
# 构造:l(i+1) = l(i) + l'(i) * delta_s + 1/2 * l''(i) * delta_s^2 + 1/6 * l'''(i) * delta_s^3
A_ll = -eye_n + np.eye(n, k=1)
A_ldl = -delta_s * eye_n
A_lddl = -0.5 * delta_s * delta_s * eye_n
A_l = (np.block([
[A_ll, A_ldl, A_lddl]
]))
# 构造:l'(i+1) = l'(i) + l''(i) * delta_s + 1/2 * l'''(i) * delta_s^2
A_dll = zero_n
A_dldl = -eye_n + np.eye(n, k=1)
A_dlddl = -delta_s * eye_n
A_dl = np.block([
[A_dll, A_dldl, A_dlddl]
])
A_ul = np.block([
[eye_n, zero_n, zero_n],
[zero_n, zero_n, zero_n],
[zero_n, zero_n, zero_n]
]) # 3n*3n
# 初始化设置
A_init = np.zeros((3, 3 * n))
A_init[0][0] = 1
A = sparse.csc_matrix(np.row_stack((A_ul, A_l, A_dl, A_init)))
low_bound[5 * n] = 1
up_bound[5 * n] = 1
l = np.array(low_bound)
u = np.array(up_bound)
# Create an OSQP object
prob = osqp.OSQP()
# Setup workspace and change alpha parameter
prob.setup(P, q, A, l, u, alpha=1.0)
# Solve problem
res = prob.solve()
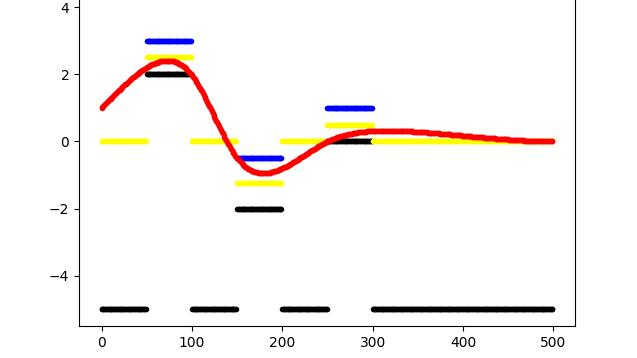
plt.plot(u[:n], '.', color='blue')
plt.plot(l[:n], '.', color='black')
plt.plot(s_ref[:n],'.', color='yellow')
plt.plot(res.x[:n], '.', color='red')
plt.show() |