
专注Python/ target=_blank class=infotextkey>Python、AI、大数据,请关注公众号七步编程!
在不同公司的许多人可能出于各种原因需要从Inte.NET收集外部数据:分析竞争,汇总新闻摘要、跟踪特定市场的趋势,或者收集每日股票价格以建立预测模型……
无论你是数据科学家还是业务分析师,都可能时不时遇到这种情况,并问自己一个永恒的问题:我如何才能提取该网站的数据以进行市场分析?
提取网站数据及其结构的一种可能的免费方法是爬虫。
在本文中,你将了解如何通过Python轻松的完成数据爬虫任务。

广义上讲,数据爬虫是指以编程方式提取网站数据并根据其需求进行结构化的过程。
许多公司正在使用数据爬虫来收集外部数据并支持其业务运营:这是当前在多个领域中普遍的做法。
我需要了解什么才能学习python中的数据抓取?
很简单,但是需要首先具备一些Python和html知识。
另外,需要了解两个非常有效的框架,例如,Scrapy或Selenium。
接下来,让我们学习如何将网站变成结构化数据!
为此,首先需要安装以下库:
如果你使用的是Anaconda,配置起来会非常简单,这些软件包都已预先安装。
如果不是使用Anaconda,需要通过如下命令安装工具包:
pip install requests
pip install beautifulsoup4
pip install lxml
pip install pandas
我们要抓取哪些网站和数据?
这是爬虫过程中首先需要回答的问题。
本文就以爬取Premium Beauty News为例进行演示。
该以优质美容新闻为主,它发布了美容市场的最新趋势。
查看首页,你会看到我们要抓取的文章以网格形式组织。

多页面的组织如下:

当然,我们仅要提取出现在这些页面上的每篇文章的标题,我们将深入每个帖子并获取我们需要的详细内容,例如:

前面,已经介绍了基本的内容以及需要用到的工具包。
接下来,就是正式编码实践的步骤。
首先,需要导入基础工具包:
import requests
from bs4 import BeautifulSoup
import pandas as pd
from tqdm import tqdm_notebook
我通常定义一个函数来解析给定URL的每个页面的内容。
该函数将被多次调用,这里将他命名为parse_url:
def parse_url(url):
response = requests.get(url)
content = response.content
parsed_response = BeautifulSoup(content, "lxml")
return parsed_response
提取每个帖子数据和元数据
首先,我将定义一个函数,该函数提取给定URL的每个帖子的数据(标题,日期,摘要等)。
然后,我们将遍历所有页面的for循环内调用此函数。
要构建我们的爬虫工具,我们首先必须了解页面的基本HTML逻辑和结构。以提取帖子的标题为例,讲解一下。
通过在Chrome检查器中检查此元素:

我们注意到标题出现在 article-title类的h1内。
使用BeautifulSoup提取页面内容后,可以使用find方法提取标题。
title = soup_post.find("h1", {"class": "article-title"}).text
接下来,看一下日期:

该日期显示在一个span内,该范围本身显示在row sub-header类的标题内。
使用BeautifulSoup将其转换为代码非常容易:
datetime = soup_post.find("header", {"class": "row sub- header"}).find("span")["datetime"]
下一步就是摘要:

它在article-intro的h2标签下:
abstract = soup_post.find("h2", {"class": "article-intro"}).text
现在,需要爬取帖子的全文内容。如果已经理解了前面的内容,那么这部分会非常容易。
该内容在article-text类的div内的多个段落(p标签)中。

BeautifulSoup可以通过以下一种方式提取完整的文本。而不是遍历每个每个p标签、提取文本、然后将所有文本连接在一起。
content = soup_post.find("div", {"class": "article-text"}).text
下面,让我们把它们放在同一个函数内看一下:
def extract_post_data(post_url):
soup_post = parse_url(post_url)
title = soup_post.find("h1", {"class": "article-title"}).text
datetime = soup_post.find("header", {"class": "row sub-header"}).find("span")["datetime"]
abstract = soup_post.find("h2", {"class": "article-intro"}).text
content = soup_post.find("div", {"class": "article-text"}).text
data = {
"title": title,
"datetime": datetime,
"abstract": abstract,
"content": content,
"url": post_url
}
return data
如果我们检查主页的源代码,会看到每个页面文章的标题:

可以看到,每10篇文章出现在1个post-style1 col-md-6标签下:
下面,提取每个页面的文章就很容易了:
url = "https://www.premiumbeautynews.com/fr/marches-tendances/"
soup = parse_url(url)
section = soup.find("section", {"class": "content"})
posts = section.findAll("div", {"class": "post-style1 col-md-6"})
然后,对于每个单独的帖子,我们可以提取URL,该URL出现在h4标签内部。
我们将使用此URL调用我们先前定义的函数extract_post_data。
uri = post.find("h4").find("a")["href"]
在给定页面上提取帖子后,需要转到下一页并重复相同的操作。
如果查看分页,需要点击“下一个”按钮:

到达最后一页后,此按钮变为无效。
换句话说,当下一个按钮处于有效状态时,就需要执行爬虫操作,移至下一页并重复该操作。当按钮变为无效状态时,该过程应停止。
总结此逻辑,这将转换为以下代码:
next_button = ""
posts_data = []
count = 1
base_url = 'https://www.premiumbeautynews.com/'
while next_button isnotNone:
print(f"page number : {count}")
soup = parse_url(url)
section = soup.find("section", {"class": "content"})
posts = section.findAll("div", {"class": "post-style1 col-md-6"})
for post in tqdm_notebook(posts, leave=False):
uri = post.find("h4").find("a")["href"]
post_url = base_url + uri
data = extract_post_data(post_url)
posts_data.Append(data)
next_button = soup.find("p", {"class": "pagination"}).find("span", {"class": "next"})
if next_button isnotNone:
url = base_url + next_button.find("a")["href"]
count += 1
此循环完成后,将所有数据保存在posts_data中,可以将其转换为漂亮的DataFrames并导出为CSV或Excel文件。
df = pd.DataFrame(posts_data)
df.head()
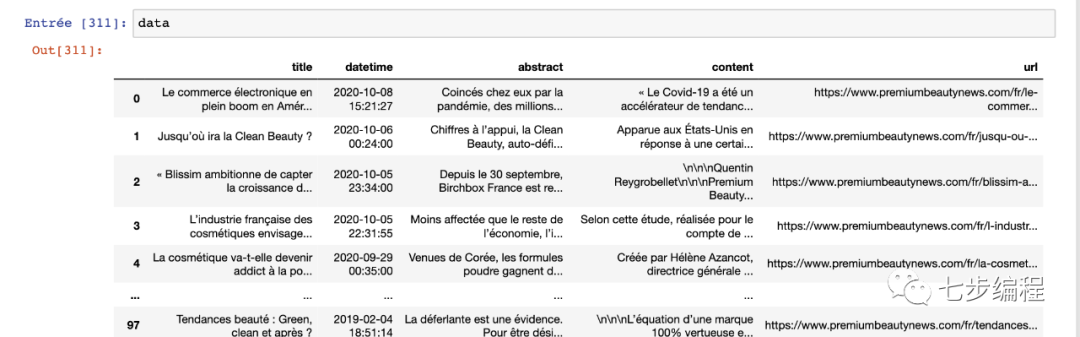
到这里,就把一个非结构化的网页转化成结构化的数据了!













