MLOps 是将机器学习、数据工程和 DevOps 融合在一起,从而实现机器学习模型的高效迭代和持续稳定地应用于生产业务的一套方法架构。所以它是一套实践方法论,是一套架构方案。
① 数据产品团队:定义业务目标,衡量业务价值。
② 数据工程团队:采集业务数据,然后对数据进行清洗转换。
③ 数据科学家团队:构建 ML 解决方案,开发相应的特征模型。
④ 数据应用团队:模型应用,对特征进行持续的监控。

(1)样本准备,产品业务团队定义业务范围,确定建模的目标,选择样本人群准备训练集。
(2)数据处理,需要对数据进行缺失值、异常值、错误值、数据格式的的清洗,使用连续变量、离散变量、时间序列等进行数据转换。
(3)特征开发,数据处理完成后就可以进行特征衍生,金融特征主要通过审批逻辑衍生,行为总结量化,穷举法,去量纲,分箱,WoE,降维,One-Hot 编码等进行特征衍生,之后依据特征质量,比如特征指标(ks、iv、psi)或者预计逾期率等进行特征筛选。
(4)模型开发,要进行算法的选择和模型的拟合。
(5)模型训练,使用测试数据集进行模型算法的测试验证,进行参数的调优。
(6)模型应用,模型开发好之后就需要进行线上化的一个部署。
(7)模型监控,上线后需要持续的监控和模型的迭代优化。

众安金融,一方面为普惠人群提供公信征信支持,另一方面也为银行等资金机构来提供风险缓释,助力普惠金融。众安金融为无抵押的纯线上消费贷款平台提供信用保证保险服务,也为其他金融机构提供信用保证保险服务。
众安保险作为保险公司在其中承担理赔的责任,所以就要求我们需要对风险进行全面识别、准确计量、严密监控。我们搭建了以大数据为基础、以风控规则与模型为策略,以系统平台为工具的大数据风控体系。通过利用大数据与个人信用的关联挖掘出大量的用户风险特征和风险模型,从而提升风控的预测能力。
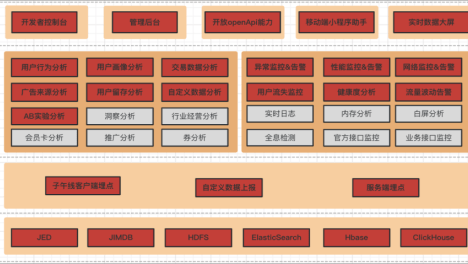
随着风控策略的精细化,模型应用的规模化,特征使用的实时化,对我们的特征开发和模型应用提出了更快速更实时的要求,所以我们就开始尝试进行特征平台体系化的实践。

(1)大数据平台:数据开发工程师使用大数据平台的能力采集到相关的业务数据,构建基于主题域的离线数据体系,同时把相应的数据回流同步到在线 NoSQL 存储引擎,提供给实时特征平台使用。
(2)特征工程:数据科学家在大数据平台进行特征工程的建设,使用离线数仓进行特征的挖掘和特征的选择。
(3)机器学习平台:数据科学家借助机器学习平台可以进行一站式的模型开发和应用。
(4)实时特征平台:开发好的特征和模型需要在实时特征平台进行注册,在实时特征平台配置好相关的信息后,就可以通过实时特征平台的数据服务能力,提供上游业务的特征查询和模型应用的能力。

众安金融实时特征平台服务于金融业务全流程,包含金融线上的核心业务场景如登录,准入,授信,支用,提额等实时前台场景,后台业务场景更多是批量的特征调用场景,此外还有催收也有对于特征和模型的使用,一开始特征平台的初衷是为风控体系服务,随着业务的发展,模型也逐渐使用到了用户营销场景和一些资源位的用户推荐服务中。这里值得注意的是,对风控业务了解的同学就会知道,一次风控策略会有多个风控规则,每个风控规则会查询多个特征数据,所以一次业务交易对于实时特征平台来说可能就会放大到几百倍的调用。

(1)交易行为数据:包含授信,借款申请、还款的数据,调额和逾期数据等业务数据。
(2)三方征信数据:需要对接三方征信机构的接口。
(3)设备抓取数据:在用户授权允许的情况下获取设备相关信息。
(4)用户行为数据:通过用户行为埋点获取。

面对众多的特征数据源,这就要求我们实时特征平台具备丰富的数据接入能力,实时的数据处理能力,对于大量的特征需求也要求特征平台具备高效的特征加工配置化能力,实时的业务调用要求平台有快速的系统响应能力,我们也是围绕这些核心能力的要求进行特征平台的技术选型和架构设计。经过了技术迭代选型,我们采用了 Flink 作为实时计算引擎,使用阿里云的 TableStore 作为高性能的存储引擎,然后通过微服务化的架构实现了系统的服务化和平台化。

这张图是我们的实时特征平台的业务架构图,可以看到图的底层是特征数据源层,中间层是实时特征平台的核心功能层,上层是整个特征平台体系的业务应用层,特征平台主要有四个数据源:
(1)征信数据网关:提供人行征信等征信机构的用户信用数据,需要通过实时的接口对接来查询征信数据。
(2)三方数据平台:提供外部数据服务商的数据,通过调用三方数据接口服务完成实时数据对接。
(3)实时计算平台:实时接入业务系统的交易数据,用户行为数据和抓取设备数据,通过实时计算后回流到 NoSQL 在线存储引擎。
(4)离线调用平台:离线数据在阿里云的 MaxComputer 计算后同步到 NoSQL 存储,实现历史数据的回流,从而支撑用户全业务时间序列的特征计算,此外一些非实时指标也需要在离线数仓加工完成后再回流到 NoSQL 存储引擎。
实时特征平台的核心功能:
(1)特征网关:特征网关是特征查询的出入口,具备鉴权限流,特征数据编排等功能。
(2)特征配置:为了支持特征的快速上线,特征平台实现了特征的配置化能力,包含三方数据特征配置,实时业务特征配置,互斥规则特征配置,模型特征配置能力。
(3)特征计算:特征计算是通过微服务化的子系统来实现的,主要有三方特征计算,实时特征计算,反欺诈特征计算,模型特征计算。
(4)特征管理:特征管理后台提供了特征变量生命周期管理能力,模型的元数据管理,还有特征跑批的任务管理。
(5)特征监控:具备特征调用全链路查询能力,对于特征计算失败,特征值异常值,模型PSI值波动进行实时告警,此外也提供了特征使用情况等统计分析大盘报表。

(1)查询方式:调用三方征信机构的实时接口获取报文数据然后进行数据处理获取特征结果,出于降本考虑,我们还会实现一套缓存机制,对于离线场景减少调用三方的次数。
(2)创新点:三方数据接入引擎可以通过纯配置化的方式接入三方的数据接口,通过特征加工引擎实现自动化的特征生成,通过可视化界面提供配置化的能力,最后通过接口提供给上游使用三方特征计算服务。
(3)解决的难点:三方数据与配置化接入的难点是数据服务商的加密方式、签名机制多样性、复杂性,三方数据接入引擎通过内置一套加解密函数和支持自定义函数的能力,结合函数的链式组合方式,完成了各种复杂的三方数据加解密的配置化的实现。

实时业务数据的接入由两部分组成,首先是通过 Flink 实时监听业务数据库的 Binlog 数据写入到实时数仓,还有一部分使用 Spark 完成历史数据的回补,结合离线数据和实时数据就可以支持基于全量时序数据的特征加工能力,为了支持高性能的实时特征查询,实时数据和离线数据都会回流到 NoSQL 存储引擎。对于不同的数据,我们也会考虑不同的存储引擎,业务交易数据主要是用 TableStore 作为存储引擎,用户行为特征数据使用 redis 为主,用户关系图谱数据用图数据库进行存储,从整个流程来看,现在的数据体系是采用成熟的 Lambda 架构。

我们实时特征平台的架构基本如上图,上游业务经过特征网关进行特征的查询,特征网关会进行特征查询权限的验证,限流控制和特征查询任务异步分发,特征网关首先根据特征元数据信息路由到不同的特征数据源,从特征数据源查询到原始数据之后会再路由到不同的特征计算服务进行特征的加工。三方特征是从三方数据平台和征信网关查询到的原始报文数据之后加工成为对应的特征;业务特征计算用于加工内部业务系统的实时特征。
信贷特征是通过实时业务数据同步后进行特征加工计算,离线特征服务是在离线数仓 MaxComputer 完成的特征加工计算。反欺诈特征计算用于对用户登录设备信息,用户行为数据和用户关系图谱等相关特征的加工。
在基础的三方特征,业务特征计算完成后,就可以直接提供给上游业务使用,此外模型服务也会依赖这些基础特征,模型特征计算是借助机器学习平台的能力来实现的,我们的机器学习平台提供了模型的训练,测试,发布等一体化功能,特征平台集成了机器学习平台的能力从而实现了模型特征的自动化和配置化。

我觉得实时特征计算方案有两种,第一种实时同步原始业务数据,然后在实时计算任务同时实现特征的加工,这是传统的 ETL 模式,这种方式的优点是特征查询非常高效,查询性能好,但是实时任务计算复杂,需要大量实时计算资源,需要特征衍生的话也是比较困难;另外一个方式是实时同步原始业务明细数据,但是特征加工是即时进行,也就是说特征查询时再进行特征的计算,这样方式特征查询计算繁重,需要高速特征查询引擎支持,但是实时任务比较简单,特征衍生也比较方便,这个较新的 ELT 模式。出于我们业务对于特征频繁衍生的要求和节省实时计算资源的考虑,我们选择了第 ELT 的即时加工特征的方案。

实时特征数据流通过 Kafka+Flink 实现实时数据的同步,同时也使用 Spark 从离线数仓数据回补完成全量时序数据的采集,实时业务数据主要是用 TableStore 作为存储引擎,结合实时特征计算引擎和 ID-MApping 的多主体查询能力实现了特征的配置化生成。
除了通过 Flink 实时采集的数据外,还有部分数据需要调用业务系统的接口来获取,这种数据也可以注册为特征数据引擎的元数据,和存储在 TableStore 里的数据一样进行配置化使用。我们采用了阿里云的 TableStore 这个比较稳定的高速查询引擎来支持实时特征查询,但是其实云产品的成本也需要考虑的,所以大家也需要根据本身的现状选择合适的方案。
由于我们存在多条产品线,每个产品线的用户主键也都不同,而金融业务场景主要是以用户身份证,用户手机号等维度进行特征的查询,因此我们抽象了一套用户实体关系的 ID-Mapping 表,实现了身份证,手机号等维度到用户主键的关联关系,特征查询时首先会根据特征入参查询 ID-Mapping 表获取用户 ID,然后再根据用户 ID 查询用户业务明细数据,主要的业务明细数据包含用户授信数据,支用明细,还款明细,额度明细,逾期明细的用户业务数据。这里我们踩过的一个坑是主副表同时更新的场景,我们把主副表存储为一份特征数据,我们主要是使用 column family 的方式存储数据,所以在高并发的场景,可能会造成主副表同时更新带来的不一致的情况,我们现在是通过一个窗口任务实现数据的补偿。下图是主要的业务数据图:


早期的特征加工是通过开发人员写代码来实现的,随着特征需求增加,为了支撑特征的快速上线,我们借助表达式语言和 Groovy 实现了一套基于特征计算函数的特征配置化能力,结合 ID-Mapping 实现了一个特征计算引擎,计算过程可以分为如下几步:
(1)创建实时 Flink 任务把用户关系数据同步到 ID-Mapping 表,从而支持用户多维数据查询。
(2)创建实时 Flink 任务把用户业务数据回流到阿里云的 TableStore,实现业务明细数据的实时同步。
(3)在特征平台的实时特征配置页面把上一步同步到 TableStore 的用户业务数据表注册为特征计算引擎逻辑数据。
(4)接下来在特征计算配置页面选择相关的特征元数据,填写特征基础信息,特征加工的函数,通过测试和上线等过程后这个特征就可以提供在线使用。
(5)特征查询时首先会根据特征查询入参查询 ID-Mapping 表获取用户 ID,然后根据用户 ID 查询 TableStore 里面的用户明细业务数据,特征计算引擎会把根据配置的特征计算表达式进行特征数据查询,计算出来的数据结果就是特征值,就和第四步提到的,会把特征组下面的所有特征都计算出来。

随着金融欺诈风险不断扩大,反欺诈形势也越来越严峻,特征平台也不可避免的需要支持反欺诈特征的查询需求,总结下了我们的反欺诈特征分类如下:
(1)用户行为特征:主要是基于埋点的用户行为数据进行特征的衍生。比如用户启动的 APP 的次数、页面访问的时长,还有点击的次数和在某个输入框输入的次数等。
(2)位置识别特征:主要是基于用户的实时地理位置信息,加上 GeoHash 算法能力,实现位置特征的数据计算。
(3)设备关联特征:主要是通过用户关系图谱来实现,通过获取同一个设备下关联到用户的情况,可以快速地定位羊毛党等欺诈行为。
(4)用户图谱关系特征:通过实时的获取用户在登录、注册、授信、资用等关键业务场景的设备信息,结合用户三要素和他的一些联系人信息,构建图谱关系,然后通过查询用户的邻边关系、用户关联的用户是否有黑灰名单的情况,进行风险识别。
(5)用户社群特征:通过判断社群的大小、社群里用户行为的表现,提炼社群规则特征。

反欺诈特征计算的数据流程和实时特征计算数据流程类似,除了数据源来源于实时业务数据外,反欺诈场景更关注是埋点的用户行为数据,抓取的用户设备数据,提取的用户关联关系数据,用户行为的数据会通过埋点平台(XFlow)上报到 Kafka,这些数据也会是使用 Flink 进行实时加工计算,不过和实时业务特征处理的区别是反欺诈特征是在实时数仓里面直接计算好之后存储到 Redis,图数据库等存储里面,这个是为了满足反欺诈特征查询的高性能要求,此外反欺诈场景也更关注实时的数据变化。从上图可以了解到,反欺诈特征通过 HTTP API 的接口方式为特征网关提供特征计算服务。

用户关系图谱的建设情况,整体设计思路如下:
(1)首先是对于图的数据源的选择,要想构建比较有价值的用户关系图谱,一定要找到准确的数据进行图建模。关系图谱的数据源主要来自用户数据,比如手机号、身份证、设备信息、用户三要素,联系人等相关数据
(2)第二就是图数据存储引擎选型,需要关注的是引擎的稳定性,数据的实时性,集成的方便性,查询的高性能,存储引擎的选择非常重要,现在市面上有不少图数据库的技术,选型的过程中其实也碰到过不少的坑,一开始我们选择的 orientdb,在大数据量的情况下就出现了很多不稳定的问题,所以需要重点考虑大数据量的处理能力和存储引擎的稳定性,一定要经过全面的技术调研才能进行生产的实践
(3)其次就是需要考虑图数据相关的算法支撑能力,除了基本的相邻边查询能力,是否有比较丰富的图算法支持,比如在反欺诈场景使用到的是社群发现算法
(4)最后需要通过 API 的方式提供图数据服务,反欺诈应用场景提供图数据特征的服务外,还可以赋能给营销推荐场景
经过多方位的选型调研,最终选择了 NebulaGraph 作为图数据库,它采用的是 shard-nothing 的分布式存储,能够支持万亿级别的一个大规模的机型的图的计算。NebulaGraph 的相关信息可以从他们的官网了解,这里就不赘述了。

通过模型团队对用户关系图谱的数据挖掘,从用户社群的年龄分布,消费预估水平分布等多维度统计数据出发,我们提取出了一些图特征,这边列举了一批以供大家参考:
(1)第一方欺诈:通过图认为同一个人申请多次,而且每次提交的联系人等关联信息都不太一致,可以认为它是有第一方欺诈的嫌疑。
(2)疑似中介代办:有部分人的申请人都关联到了相同一个联系人的手机号。
(3)疑似信息冒用:就是一个人的手机号可能被很多人使用,可能它出现了信息的泄露。
(4)疑似团伙欺诈:看关系图谱社群节点的规模数量是否超过了一定的规模。
反欺诈策略规则。通过一两个特征可能没办法精确地对反欺诈行为进行定位,需要来组合多类的特征,形成反欺诈策略规则,从而在多方面提升对用户反欺诈识别的准确度。
A1:整个实时业务的采集我们是使用 Flink 完成明细数据的清洗,把 DWD 层的数据回流到 TableStore,然后通过实时特征计算引擎来实现数据的关联,设置多个计算因子,然后通过这种方式把多条数据进行关联,支持最终特征的产生。比较少在 Flink 里面进行这个数据的关联 Join 查询,也就是现在比较流行的 ELT的模式。
A2:特征计算是基于特征组维度,一个特征组下面可能会有几十上百个特征,我们的现在的这个计算框架主要性能的消耗是在对于特征原始数据的查询,只要把原始数据查询出来,特征口径计算都是在内存里面完成。那么就需要有底层高性能的查询引擎来支持,我们现在依赖于阿里云的 TableStore 查询引擎来实现快速的数据查询能力。
A3:对于模型的算法不是我所在行的,我的理解是可以从特征质量和特征算法指标入手,但是没有通用的一个解决方案,要根据实际的业务数据进行算法的验证和调优,才能够得到答案。
A4:现在采用的是联通分量算法。我们关系图谱不只是在反欺诈特征计算使用,也给反欺诈团队来做反欺诈调查使用,他们会根据有欺诈嫌疑的用户,对我们的关系图谱进行反向的验证,通过实际的调研来看算法的效果。
我们是使用 Spark Graphx 的连通分类算法,通过找到子图顶点 ID,连通分量算法计算每个子图中的每个顶点所连接的最小顶点值,然后使用同一个顶点 ID 的下所有的节点 ID 组合生成一个新的 ID 作为社群 ID。
A5:主要取决于图社群的图关系数据量,如果是查询普通的用户,整个用户的节点不会有太多,基本上会在十个节点以内。但是如果这个人确实是中介或者说有反欺诈嫌疑的用户,那他的子图会非常大,确实会出现查询上的性能超时的情况。应用到反欺诈场景,我们会设置兜底方案,比如说反欺诈的图特征接口响应超过了 100 毫秒,我们就会默认让这个用户通过,尽量不要去影响用户实时的业务体验。
A6:反欺诈的特征更关注用户的行为特征,更偏向于对用户行为的挖掘。
A7:现在我们每天特征的查询量会在八九千万的级别。实时特征的实时任务时长,依赖于 Flink 的实时能力,在几十毫秒之内就可以完成这个数据的同步。我们的特征查询依赖于阿里云 TableStore 的能力,每次的特征查询也都在 100 毫秒左右,所以性能还是比较有保障的。
A8:是有可能缺失的。因为现在是监听 Binlog 的方式实时写入的,如果在业务高峰期,特别是在有些跑批业务场景的这个情况下,可能 Binlog 的数据量非常大,那我们整个实时数据的采集耗时可能比平时要更长。比如说这个用户在授信过程后马上进行支用的话,他的一些授信的数据还没有完全及时地写到在线查询引擎,可能这一次的实时查询就会有缺失的情况。
A9:我们现在的存储其实还是基于用户维度的存储方式,主键是用户的 userID ,那我们会通过 table store 的 range 查询的方式,把用户相关的所有数据都查询出来。
其实在金融场景,不像电商或者内容查询的业务场景,一个用户的交易数据、业务数据并不太多,其实不会存在有太大的效率问题。
A10:优惠券 ID 等可能在营销场景有不同的维度和特征。在风控业务场景,特征维度基本上基于人维度的,比如用户身份证、手机号,还有用户这个组件的维度,比较少见基于这种优惠券 ID 维度的特征。
A11:现在还没有这方面的探索。
A12:这个会有超过的,最大窗口的范围会在三天。但是实时特征场景,窗口基本上不会太大,一般是分钟级别。对实时性要求不高的一些特征场景,我们可以支持在 3 天的窗口。这个比较耗费资源,这种情况会比较少。
A13:如果相对于整个特征体系来说的话,是不多的。但是我们的模型覆盖了整个金融业务领域,营销场景其实也有,具体数量可能不太好透露。
现在我们遇到的问题主要是特征的开发衍生和实际的线上化的特征应用是由两个团队去开发,之间的实现会有些不一致的情况。在模型开发的时候,它依赖的是离线的特征挖掘。那在生产时候我们是用实时特征的来去作为模型的入参变量,数据会有所差异,对于模型的 PSI 稳定性就会有一些影响。
A14:这是个非常大的话题,现在比较流行的流批一体化的方案也是在尝试解决这个问题。从我的理解来说,首先 lambda 架构可能要做一些调整,通过数据湖的方式来实现离线实时的同一份存储。引擎方面要统一和存储方面要统一,当然这个成本会比较大。最后就是特征口径的开发,在特征挖掘开发的时候的口径直接应用到生产中,具于统一的口径进行生成应用,那这样才能达到和之前特征开发口径一致。
A15:这个是会经常碰到的一些问题。比如说模型和决策引擎依赖特征是三方的特征,那在三方不可用的情况下,我们需要去怎么处理。这种情况要看我们对这个特征的依赖情况,如果是强依赖,那我们可能等待这个实时特征能够成功获取,然后再跑真正的模型和策略。如果是弱依赖,那在模型的开发的时候,就会考虑这种情况,会用其他的特征或者其他的方式进行处理。那决策引擎同样也是如此,可以定制不同的决策规则来规避这种情况。