

新智元报道
编辑: Lumina 桃子
【新智元导读】清华与微软合作提出了一种全新「思维骨架」(SoT),大大减少了LLM回答的延迟,并提升了回答的质量。
由于当前先进的LLM采用了顺序解码方式,即一次生成一个词语或短语。
然而,这种顺序解码可能花费较长生成时间,特别是在处理复杂任务时,会增加系统的延迟。
受人类思考和写作过程的启发,来自清华微软的研究人员提出了「思维骨架」(SoT),以减少大模型的端到端的生成延迟。

论文地址:https://arxiv.org/pdf/2307.15337.pdf
SoT引导LLM,首先生成答案的骨架,然后进行并行API调用或分批解码,并行完成每个骨架点的内容。
SoT不仅大大提高了速度,在11个不同的LLM中可达2.39倍,而且还可能在多样性和相关性方面提高多个问题类别的答案质量。
研究人员称,SoT是以数据为中心优化效率的初步尝试,揭示了推动LLM更像人类一样思考答案质量的潜力。
SoT,让大模型并行解码
目前,最先进的LLM的推理过程依旧缓慢,交互能力大大减分。
对此,研究人员总结出LLM推理慢的3个主要原因:
- 大模型需要大量内存,内存访问和计算。
比如,GPT-3的FP16权重需要350 GB内存,这意味着仅推理就需要5×80GB A100 GPU。即使有足够多的GPU,繁重的内存访问和计算也会降低推理(以及训练)的速度。
- 主流Transformer架构中的核心注意力操作受I/O约束,其内存和计算复杂度与序列长度成二次方关系。
- 推理中的顺序解码方法逐个生成token,其中每个token都依赖于先前生成的token。这种方法会带来很大的推理延迟,因为token的生成无法并行化。
先前的研究中,大多将重点放在大模型规模,以及注意力操作上。
这次,研究团队展示了,现成LLM并行解码的可行性,而无需对其模型、系统或硬件进行任何改动。
研究人员可以通过Slack使用Claude模型将延迟时间从22秒,减少到12秒(快了1.83倍),通过A100上的Vicuna-33B V1.3将延迟时间从43秒减少到16秒(快了2.69倍)。
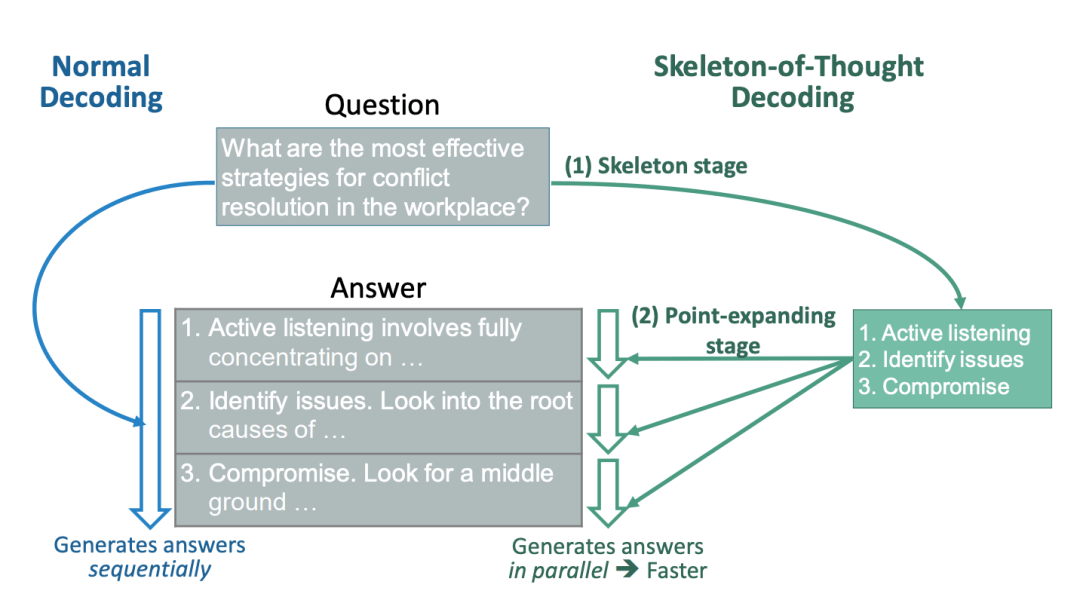
这个想法,来源于对人类自身如何回答问题的思考。
对于我们来讲,并不总是按顺序思考问题,并写出答案。相反,对于许多类型的问题,首先根据一些策略推导出骨架,然后添加细节来细化和说明每一点。
那么,这一点在提供咨询、参加考试、撰写论文等正式场合中,更是如此。
我们能够让LLM以同样的方式思考吗?
为此,研究人员提出了「思维骨架」(SoT)。具体来说,引导LLM首先自己推导出一个骨架。

在骨架的基础上,LLM可以并行地完成每个点,从而提高速度。SoT既可用于加速分批解码的开源模型,也可用于加速并行API调用的闭源模型。
最后,研究人员在最近发布的11个LLM上测试SoT。
结果显示,SoT不仅提供了相当大的加速度(最高可达2.39倍) ,而且它还可以在多样性和相关性方面提高几个问题类别的答案质量。
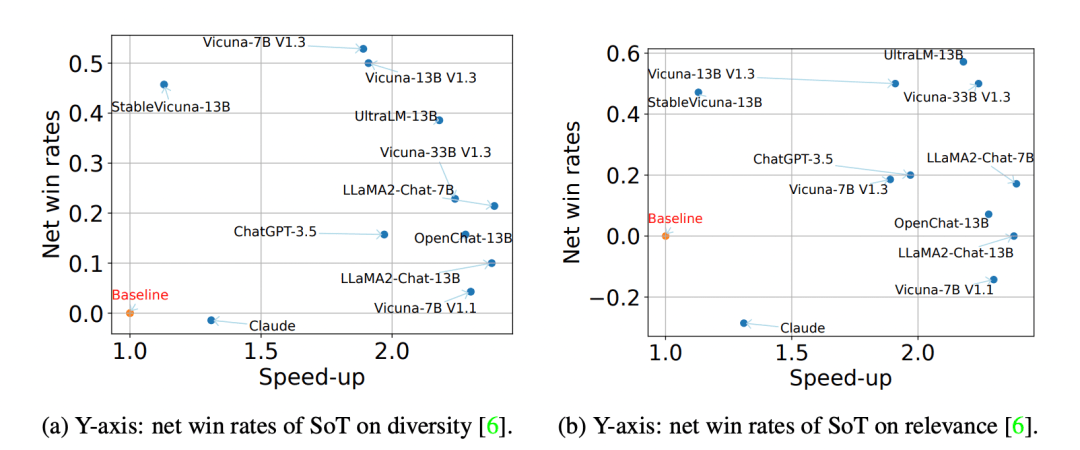
在vicuna-80的所有问题中,SoT的净胜率和与正常一代相比的速度
SoT框架
- 骨架阶段。
SoT首先使用骨架提示模版
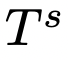
,以问题q为参数,组装一个骨架请求。编写骨架提示模板是为了引导LLM输出简洁的答案骨架。然后,研究人员从LLM的骨架答案
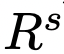
中提取B点。
- 点扩展阶段
基于骨架,让LLM在每个点上平行展开。
具体地说,对于带有索引b和骨架
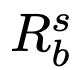
的点,SoT使用作为LLM的点扩展请求,其中
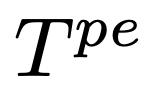
是点扩展提示模板。最后,在完成所有的点之后,研究人员连接点扩展响应来得到最终的答案。
如下,Prompt 1和 Prompt 2显示了,研究人员当前实现使用的骨架提示模板
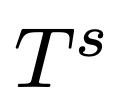
和点扩展提示模板
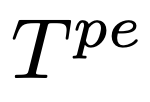
。


- 骨架提示模板。为了使输出的骨架简短且格式一致,以提高效率和便于提取要点,骨架提示模板(1)精确描述了任务,(2)使用了两个简单的示范,(3)提供了部分答案「1」为LLM继续写作。
- 点扩展提示模板。点扩展提示模板描述点扩展任务,并提供部分答案。研究人员还提供了指示「在1ー2个句子中非常简短地写出」的说明,以便LLM使答案保持简洁。
- 并行点扩展。对于只能访问API的专有模型可以发出多个并行的API调用。对于开源模型,让模型将点扩展请求作为批处理。
为什么SoT降低了解码延迟?
首先要对SoT为什么能够带来显著的端到端加速有一个高层次的理解。为了简单起见,在这里集中讨论点扩展阶段。
具有并行API调用的模型。普通方法向服务器发送一个API请求,而 SoT 并行发送多个 API 请求以获得答案的不同部分。
根据经验,研究人员观察到,在论文中使用的API的延迟与响应中的token数呈正相关。如果请求数量没有达到速率限制,SoT显然会带来加速。
采用批量解码的开源模型。普通的方法只处理一个问题,并按顺序解码答案,而SoT处理多个点扩展请求和一批答案。
实验结论
实验数据集:使用Vicuna-80数据集,它由跨越9个类别的80个问题组成,如编码、数学、写作、角色扮演等。
模型:对11个最近发布的模型进行SoT测试,其中包括9个开源模型和2个基于API的模型)。
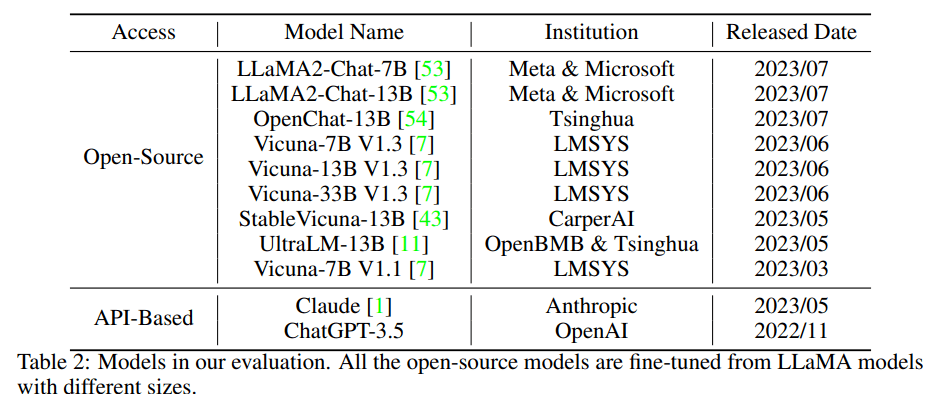
评估的模型,所有的开源模型都是根据不同大小的LLaMA模型进行微调的
效率评估:
1. SoT减少不同模型上的端到端延迟
图4a显示了应用SOYT后,每个模型在所有问题类别中的平均加速。
应用SoT后,11个模型中,有6个模型速度有2倍以上的提升(即LLaMA2-Chat-7B,LLaMA2-Chat-13B,Vicuna-7B V1.1,OpenChat-13B,Vicuna-33B V1.3,UltraLM-13B)。
在ChatGPT-3.5,Vicuna-13B V1.3和Vicuna-7B V1.3上则有1.8倍以上的速度提升。
但在StableVicuna-13B和Claude中,速度几乎没有提升。
如果排除数学和代码的问题类别,速度提升会较排除前略高,如图4b所示。
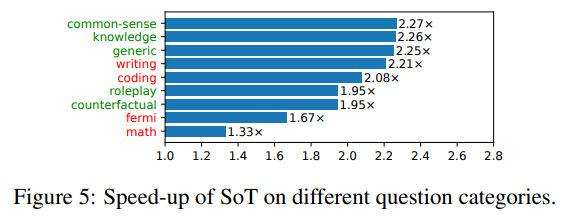
2. SoT减少不同类别问题的端到端延迟
图5显示了每个问题类别在所有模型中的平均速度提升。
那些SoT能够提供高质量答案的问题类别标记为绿色,不能的其他问题类别标记为红色。
当前的SoT已经可以提升所有类别问题的速度。
但对于那些SoT可以提供高质量答案的5个问题类别(即知识、常识、通用、角色扮演、虚拟情景),SoT可以将整体答案生成过程加速1.95倍-2.27倍。
3. SoT和正常生成的延迟对比
图6显示了模型正常生成和SoT生成的绝对延迟的比较。与正常生成相比,应用SoT的模型生成的速度提升是显而易见的。
而解码阶段是内容生成端到端延迟的主要原因。
因此,尽管SoT在骨架阶段比正常生成具有较高的预填充延迟,但这对总体延迟和总体速度提升几乎没有影响。
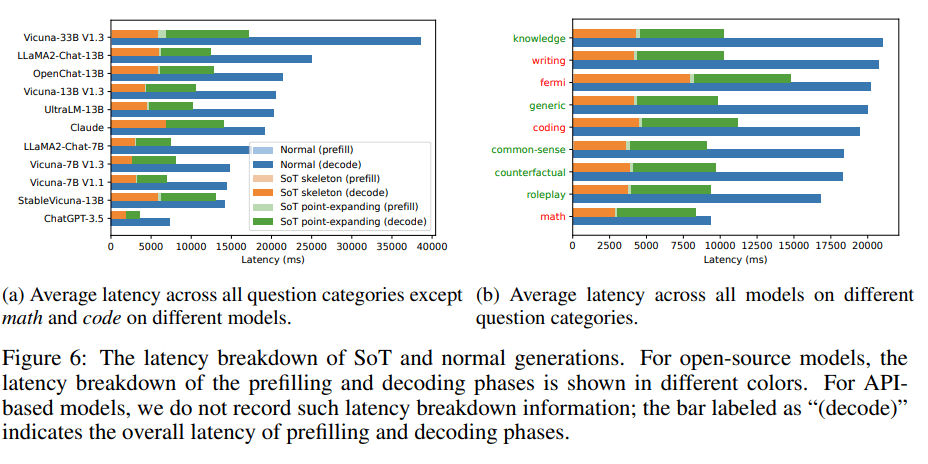
SoT和正常生成的延迟对比。对于开源模型,预填充和解码阶段的延迟分解以不同的颜色显示。对于基于API的模型,研究不记录此类延迟分解信息:标记为「decode」的柱状图表示预填充和解码阶段的整体延迟。
质量评估:
为了比较正常的顺序生成(以下简称为正常)和SoT生成的答案质量,研究采用了两个基于LLM的评估框架: FastCha和LLMZoo。
评估过程是向LLM评判器(本研究中为ChatGPT-3.5)展示一个问题和一对答案(由正常和SoT生成),并询问其偏好。
回答可能是SoT的答案胜出、与正常答案并列、输给正常答案。
1. 整体质量:
图7显示了使用FastChat和LLMZoo两个指标下使用SOT的模型在所有问题下的赢/平/输率。
在SoT严格优于基线时,两个指标之间存在差异(49.0% vs.10.4%)。
但这两个指标都认为,在超过76%的情况下,SoT并不比基线(正常生成)差。
对于FastChat指标,研究人员还展示了排除数学和编码问题(SoT不适用于这些问题,请参见3.2.2节)的比率:
在超过90%的情况下,SoT与基准相当。这表明SoT的答案保持着良好的质量。
使用FastChat和LLMZoo的「基准」,SoT相较于正常生成,在大约80%的情况下表现更好或者相当。
2. SOT在不同类别问题上的表现
图8计算了所有问题类别的净胜率(胜率-败率)。
与图7类似,LLMZoo指标下SoT的质量比FastChat的更好。
但不论在哪个框架指标下,SoT在泛型、常识、知识、角色扮演和反事实方面的表现都相对较好,而在写作、费米问题、数学和编码方面表现相对较差。
研究人员调查了如下一些问题的答案,并总结了下面的发现。
净胜率低的类别
数学
数学问题需要循序渐进的思考。如果不知道前面的步骤,很难推导出下面的步骤。SoT强调扩展顺序思考步骤,以成功解决这些问题的重要性。
相比之下,SoT要求模型首先提出解决方案的框架,不参考以前的结果独立地推断每个单独的步骤。
这两个都是具有挑战性的任务。
强模型能够得到(a)正确,但在(b)失败。
在下面的例子中,ChatGPT-35得到了正确的框架步骤。然而,在不知道第一步的结果的情况下,模型开始在第二步犯错误。

对于较弱的模型,步骤(a)甚至都很难达到正确的标准。例如,如下图所示,在 Vicuna-13B V1.3的 SoT 解决方案中,第三步「应用箔片」是突然出现的。
这使 SoT 的解决方案并不正确(尽管普通代的解决方案也不正确)。

编码
在大多数情况下,模型能够在框架阶段将编码问题分解为较小的任务,但是在论点扩展阶段的生成质量很差。
这可能是由于研究人员没有仔细地为编码设计一个特殊的点扩展提示符。
在某些情况下,模型只生成一个描述,说明如何在不给出代码的情况下完成实现。


写作
写作问题通常是写一封电子邮件,一篇博客文章,或者一篇给定场景下的评论。
在FastChat和LLMZoo的详细评估结果中,最主要也是最常见的抱怨是SoT的回答不够详细。但这一点可以通过要求更多细节的点扩展提示得到改善。

净胜率高的类别
反事实,知识,常识,通用
所有这四个类别都有相同的特征:理想的答案应该包括几个相对独立的点。
在扩展细节之前,让LLM生成一个框架可以对这个问题进行更全面的讨论。
此外,将答案组织成一个点的列表使得答案更容易阅读,而普通生成的答案有时结构化程度较低,可读性较差。




角色扮演

总结以上内容,可以得出:
如果提问问题可以从多个论点出发,并且这些论点的细节可以独立扩展,SoT的表现十分良好。
但如果是需要逐步思考的问题,比如数学问题,SoT就很难发挥作用。
为了能在更广泛的问题中通用SoT,一个可行的途径是使SoT根据问题自适应地退回到1阶段的顺序生成,而不触发点扩展。
研究中的一些结果表明,某些LLMs已经能够偶尔在没有特殊提示或调整的情况下实现这一点。
质量分解: 模型
接下来,团队还研究了SoT在不同模型上的性能,计算了图9中所有模型的净赢率。
同样,团队看到FastChat和LLMZoo的两个通用指标具有不同的绝对值,但排名相似。
特别是,这两个指标都认为OpenChat-13B、Vicuna-7B V1.1、Claude、chatgpt-3.5的净胜率较低,而Vicuna-13B V1.3、 StableVicuna-13B 和 UltraLM-13B的净胜率较高。
净胜率低的模型
OpenChat-13B和Vicuna-7B V1.1。
对于较弱的模型,如OpenChat-13B和Vicuna-7B V1.1,他们不能精确地跟随SoT提示。OpenChat-13B中框架有时包含着不想要的内容。

对于OpenChat-13B和Vicuna-7B V1.1,在回答需要细节的时候,它们偶尔不会在点扩展阶段写出任何东西。
净胜率高的模型。高净胜率的模型(Vicuna-13B V1.3,StableVicuna-13B 和 UltraLM-13B)介于上述两个极端之间。
研究得出,对于能够理解SoT提示的模型,答案的质量可能会得到提高。
研究团队期望能进一步改进SoT提示或微调模型,使LLM更容易理解框架和论点扩展的提示,最终获得更好质量的答案。
质量分解:度量
所有以前的评估都使用关于答案总体质量的度量标准。
在图10中,研究人员显示了来自LLMZoo的更详细的指标,以揭示SoT在哪些方面可以改善或损害答案质量。
平均而言,可以看到SoT提高了多样性和相关性,同时损害了沉浸感和一致性。
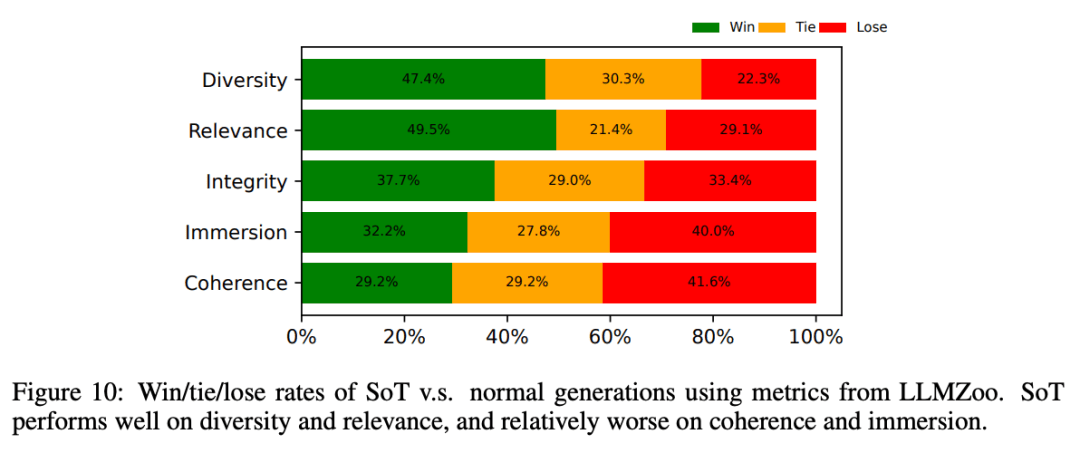
使用LLMZoo的指标,SoT相对于正常生成在多样性和相关性方面表现良好,而在连贯性和沉浸感方面相对较差。
总的来说,SoT鼓励LLMs直接从多个方面讨论答案,而无需使用填充词。
尽管回答会有一定程度的连贯性和沉浸感的损失,但SoT大大改善了答案的多样性和相关性。
然而,在回答的连贯性和沉浸感方面,大约60%的情况下SoT的生成也不比正常生成差。
更多细节参考论文。
局限性
由于提示集的限制、现有LLM判断的偏差,以及LLM属性评价的内在困难,研究人员目前对LLM问题的答案质量的评价还远不全面。
对更可靠的质量评价而言,扩展提示集,以及用人工评价补充基于LLM的评价非常重要。
然而,目前的研究主要集中在揭示潜在的效率效益上,即通过重新思考现有LLM「全序列解码」的必要性,可以实现相当大的加速。
因此,研究人员在最后将对答案质量的更彻底的评估留给了未来的工作。
参考资料:
https://arxiv.org/pdf/2307.15337.pdf


























