
近期,来自华为诺亚方舟实验室的研究者提出了 DenseSSM,用于增强 SSM 中各层间隐藏信息的流动。通过将浅层隐藏状态有选择地整合到深层中,DenseSSM 保留了对最终输出至关重要的精细信息。DenseSSM 在保持训练并行性和推理效率的同时,通过密集连接实现了性能提升。该方法可广泛应用于各种 SSM 类型,如 Mamba 和 Re.NET。
随着 ChatGPT 的突破性进展,大型语言模型(LLMs)迎来了一个崭新的里程碑。这些模型在语言理解、对话交互和逻辑推理方面展现了卓越的性能。过去一年,人们目睹了 LLaMA、ChatGLM 等模型的诞生,它们基于 Transformer 架构,采用多头自注意力(MHSA)机制来捕捉词汇间的复杂关系,尽管 MHSA 模块在模型中扮演着核心角色,但其在推理过程中对计算和内存资源的需求却极为庞大。具体来说,对于长度为 N 的输入句子,自注意力的计算复杂度高达 O (N^2),而内存占用则达到了 O (N^2D),其中 D 是模型的维度。
为了应对这一挑战,最新的研究致力于简化 Transformer 架构,以降低其在计算和空间上的复杂度。研究者们探索了多种创新方法,包括卷积语言模型、循环单元、长上下文模型,以及状态空间模型(SSMs)。这些新兴技术为构建高效能的 LLMs 提供了强有力的替代方案。SSMs 通过引入高效的隐藏状态机制,有效处理长距离依赖问题,同时保持了训练的并行性和推理的高效率。隐藏状态能够在时间维度上传递信息,减少了在每一步中访问历史词汇的计算负担。通过状态转移参数 A,隐藏状态能够将前一时间步的信息传递至当前时间步,实现对下一个词汇的自回归预测。
尽管隐藏状态在 SSMs 中起着至关重要的作用,但其在以往的研究中并未得到充分研究。不同层的权重和隐藏特征包含了从细粒度到粗粒度的多层次信息。然而,在早期的 SSMs 版本中,隐藏状态仅在当前层内流动,限制了其传递更深层信息的能力,从而影响了模型捕获丰富层次信息的能力。
为了解决这个挑战,华为诺亚方舟实验室的科研团队发表了新工作《DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models》, 提出一个适用于各类 SSM 模型例如 Mamba 和 RetNet 的 DenseSSM 方法,该方法有选择地将浅层隐藏状态整合到深层,保留了对最终输出至关重要的浅层细粒度信息,以增强深层感知原始文本信息的能力。

文章首先分析了状态空间模型(SSMs)中的隐藏状态退化问题,
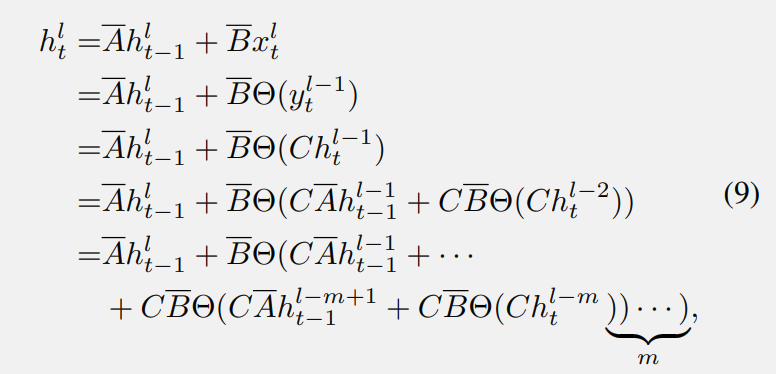
上标 “l” 表示第 l 个块。其中,Θ(·) 是从 SSM 模块的最后一个输出到输入的转换,例如卷积和前馈网络(FFN)。从公式 (7) 可以看出,从第 (l-m) 层到第 l 层的隐藏信息传递需要经过 m 个变换块和 m 次 BC 矩阵乘法。这样复杂的计算过程可能导致显著的信息丢失,这意味着在第 l 层尝试检索浅层的某些信息变得非常困难和不清晰。
方法
密集(Dense)隐藏层连接
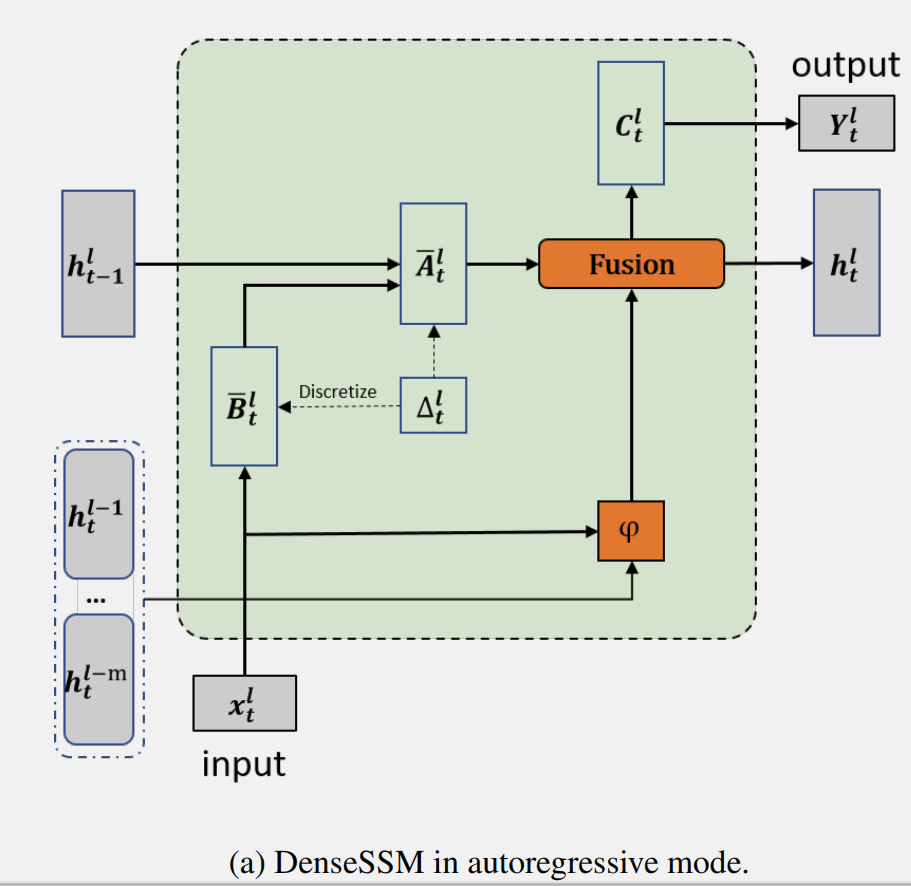
在上述分析中发现随着层深度的增加,SSM 中重要隐藏状态的衰减。因此,DenseSSM 提出了一种密集连接的隐藏状态方法,以更好地保留来自浅层的细粒度信息,增强深层感知原始文本信息的能力。对于第 l 个块,DenseSSM 在其前 m 个块中密集连接隐藏状态。
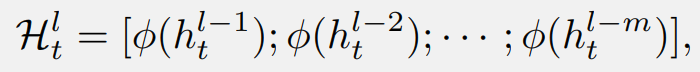
首先,收集浅层隐藏状态,并引入一个选择性转换模块 φ,同时将它们投影到目标层的子空间并选择有用的部分:
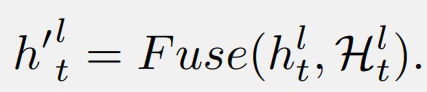
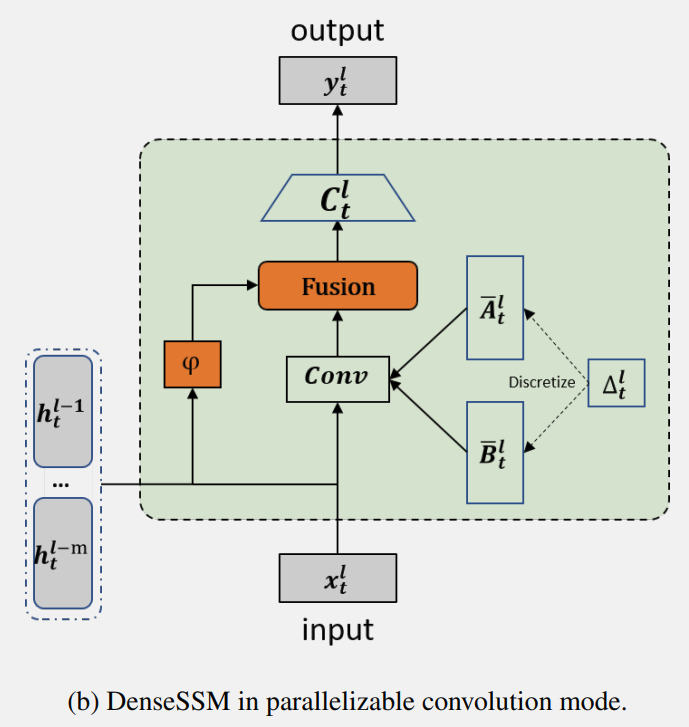
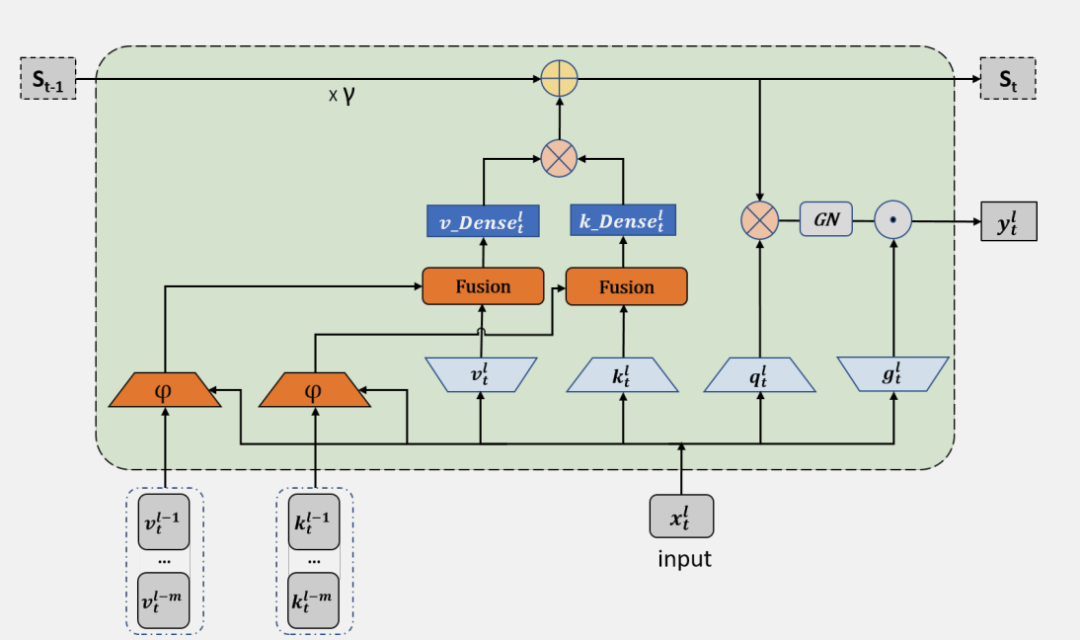
操作是融合中间隐藏向量和当前隐藏状态的函数。具有所提出的密集隐藏层连接的 SSM 被称为 DenseSSM, 下图为递归模式的 DenseSSM 示例。

DenseSSM 也可以基于卷积模式以实现高效训练。根据状态空间模型(SSM)的公式可以得到:
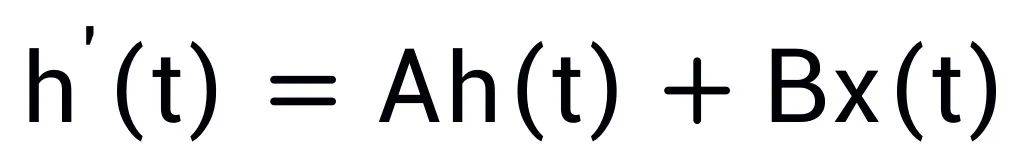

这个过程可以通过对输入序列进行卷积来实现:
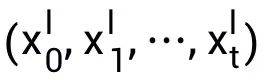
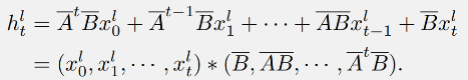
在文章所提出的 DenseSSM 中,可以获得隐藏状态加强的 SSM 的输出:
DenseSSM 方法的并行实现示例图:
Selective Transition Module (选择性转换模块)
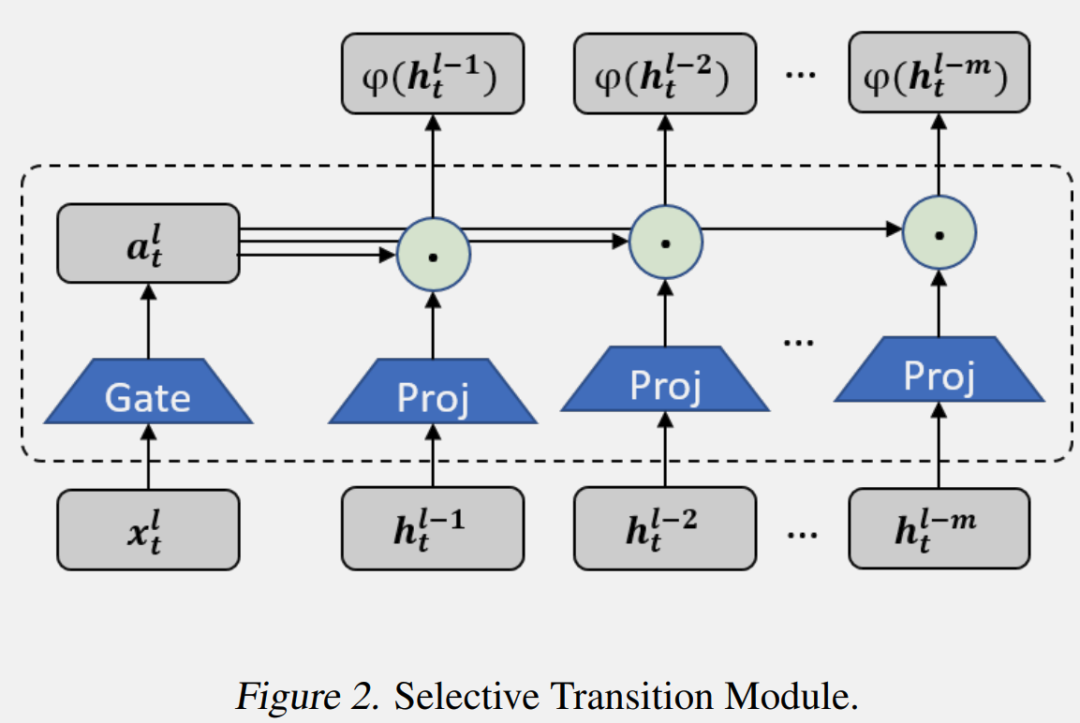
选择性转换模块 φ(·) 的目的是将输入投影到目标子空间,并同时选择隐藏信息的有用部分。通过投影层和门控选择机制实现了选择性转换模块,如上图所示。首先,前 m 个 SSM 块中的隐藏状态会被投影到相同的空间:

然后,根据输入生成门控权重,并使用它们来选择有用的隐藏状态:
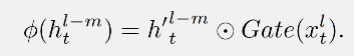
在实践中作者保持了简单且高效的实现。投影层使用线性变换实现,而门控模块则使用参数高效的带有激活函数的两层 MLP。
Hidden Fusion Module (隐藏层融合模块)
选择性转换模块后从浅层获得了选择的隐藏状态,即后,DenseSSM 方法利用一个隐藏融合模块将这些精选的浅层隐藏状态与当前层的隐藏状态结合起来。由于这些精选状态已经被投影到相同的空间,因此可以简单地将它们累加到当前层的隐藏状态上:
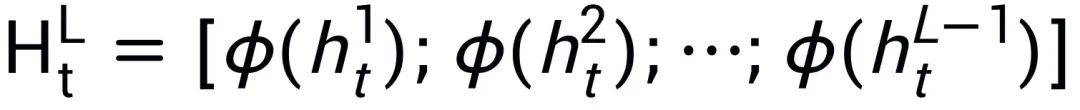
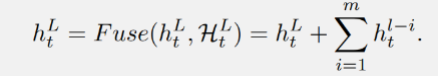
为了保持模型的高效性,其他可能的实现方式,例如拼接和交叉注意力机制没有被使用。
扩展到 RetNet
RetNet 可以被视为一种状态空间模型,它利用线性注意力来简化自注意力的计算复杂度。与标准 Transformer 相比具有快速推理和并行化训练兼得的优势。
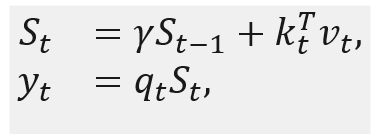
其中,是循环状态, RetNet 的密集 KV 连接执行方式如下。首先,浅层的 K 和 V 被连接起来:
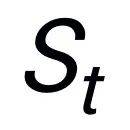
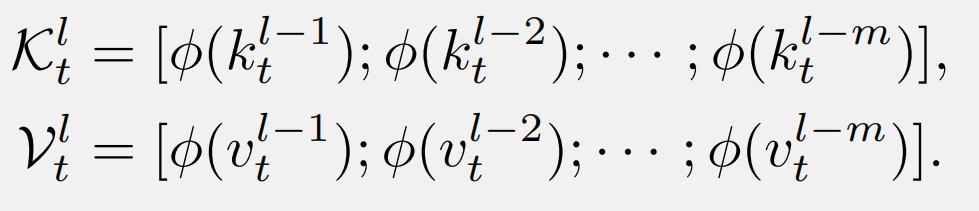
然后,这些 K 和 V 被注入到当前层的原始键(或值)中:
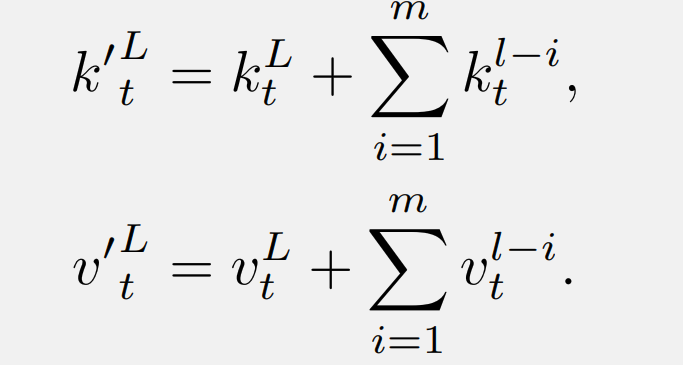
配备了使用所提出 DenseSSM 方法的密集键值(KV)连接的 RetNet 被称为 DenseRetNet,如下图所示。
此外,DenseRetNet 也可以在并行模式下实现,也就是说,可以在 GPU 或 NPU 上并行训练。DenseRetNet 的并行模式公式如下:
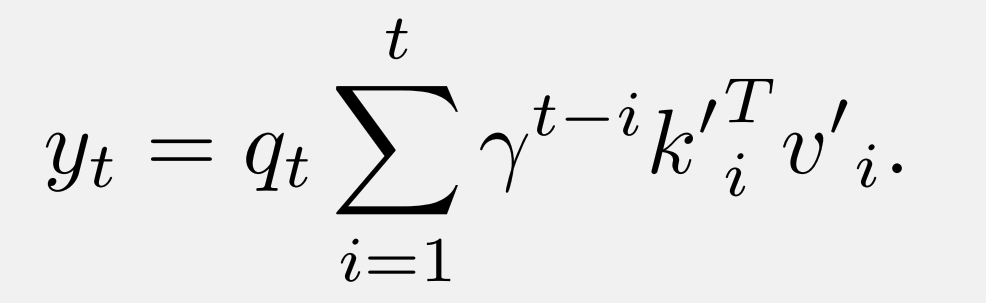
实验
文章进行了全面的实验,以验证所提出的 DenseSSM 的有效性。这些实验在不同的架构上进行,包括 RetNet 和 Mamba。
预训练数据
在实验中,选择了 The Pile 数据集的一个子集,并从头开始训练所有模型。为了确保训练集包含 150 亿(15B)个 tokens,对数据集进行了随机抽样。在所有实验中,统一使用了 LLaMA 分词器来处理这些数据。
评估数据集
在评估模型性能时,特别关注了模型在多种下游任务上的零样本和少样本学习能力。这些任务包括了一系列测试常识推理和问答的数据集,例如 HellaSwag、BoolQ、COPA、PIQA、Winograd、Winogrande、StoryCloze、OpenBookQA、SciQ、ARC-easy 和 ARC-challenge。此外,文章还报告了 WikiText 和 LAMBADA 的词困惑度指标。所有评估都通过使用 LM evaluation harness 标准化的评估工具进行,以确保评估模型能力的一致性。
实验设置
为了验证提出的 DenseSSM 机制的有效性,选择了 350M 和 1.3B 两种模型规格进行实验。所有模型都是从头开始训练的,并进行了一个 Epoch 的训练,共使用了 1.5B tokens。训练时,设置训练的 batch size 为 0.5M,序列长度为 2048 个 token。训练过程中使用了 AdamW 优化器,并采用了多项式学习率衰减,warm-up 比例设置为总训练步数的 1.5%。权重衰减设置为 0.01,梯度裁剪设置为 1。
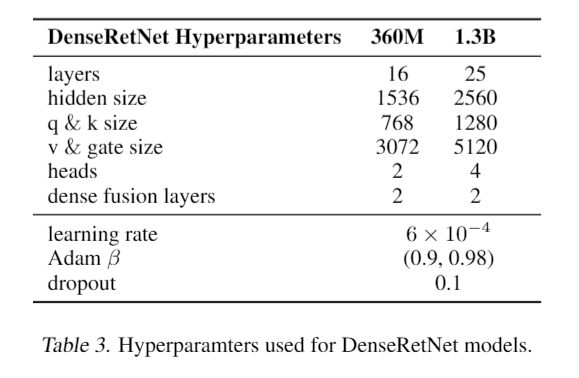
DenseRetNet 的实验
DenseRetNet 模型的大小和超参数设置详细列出如下。此外,DenseRetNet 模型中还进一步集成了全局注意力单元(GAU)。GAU 将注意力机制与前馈网络(FFN)块结合为一个单元,这使得模型能够同时进行通道混合和 token 混合。与原始的 GAU 不同,多头机制仍然被采用以实现多尺度的指数衰减,这种设计旨在提高模型对不同尺度特征的捕捉能力,从而提升性能。
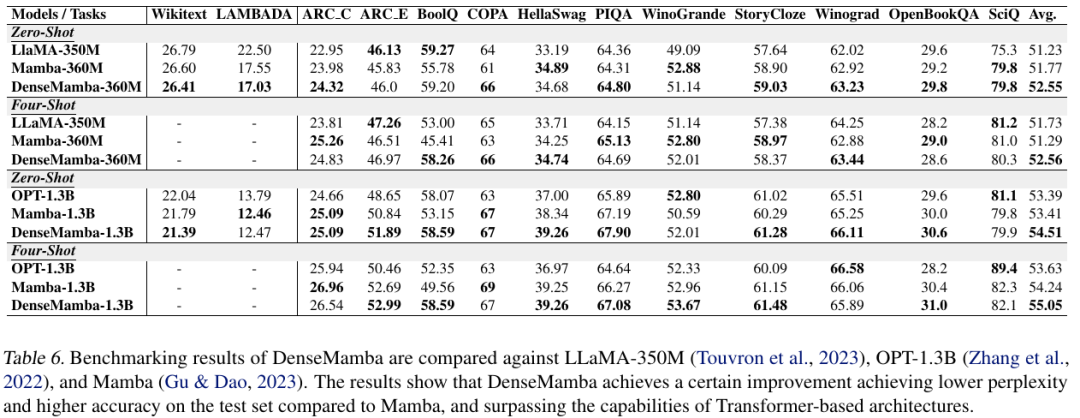
在通用语料库以及包括常识推理和问答在内的多种下游任务上,对 DenseRetNet 模型进行了评估。实验结果的比较表格显示,DenseRetNet 模型在 Wikitext 和 LAMBADA 语料库上取得了更低的困惑度。此外,在零样本和少样本设置的下游任务中,DenseRetNet 表现出了显著的优势。与 RetNet 相比,DenseRetNet 显著提升了性能,并且在与基于 Transformer 的语言模型的比较中,实现了更优越的性能表现。这些结果表明,DenseRetNet 在处理自然语言处理任务时,具有强大的能力和潜力。
DenseMamba 的实验
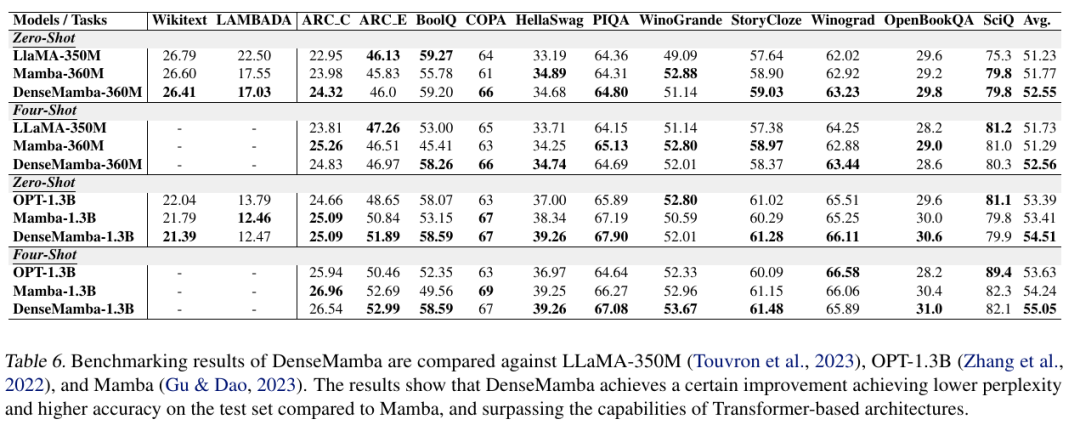
下表详细列出了 DenseMamba 模型的参数设置。由于 DenseMamba 使用的分词器相比于 Mamba 模型中使用的 GPT-NeoX 分词器规模较小,为了使参数数量相匹配,作者在模型中增加了两层。除此之外,模型结构和其他训练设置均遵循了 Mamba 论文中的描述。具体而言,对于 360M 参数的模型,学习率被设定为 3e-4;对于 1.3B 参数的模型,学习率被设定为 2e-4。在这两种情况下,均没有采用 dropout 技术。

下表比较了 DenseMamba 与相对应模型的性能。DenseMamba 在测试集上表现出卓越的困惑度和准确性,优于 Mamba 和其他基于 Transformer 的模型。
总结
文章提出了一个新的框架 ——DenseSSM(密集状态空间模型),旨在通过增强隐藏信息在不同层之间的流动来提升状态空间模型(SSM)的性能。在 SSM 中,隐藏状态是存储关键信息的核心单元,更有效地利用这些状态对于模型的基本功能至关重要。为了实现这一目标,作者提出了一种方法,即从浅层收集隐藏状态,并将它们有选择性地融合到深层的隐藏状态中,这样可以增强 SSM 对文本低层信息的感知能力。
DenseSSM 方法的设计考虑到了保持 SSM 原有的优点,如高效的自回归推理能力和高效的并行训练特性。通过将 DenseSSM 方法应用于流行的架构,例如 RetNet 和 Mamba,作者成功地创造了具有更强大的基础语言处理能力的新架构。这些新架构在公共基准测试中表现出了更高的准确性,证明了 DenseSSM 方法的有效性。


























