前言
文本生成,旨在利用NLP技术,根据给定信息产生特定目标的文本序列,应用场景众多,并可以通过调整语料让相似的模型框架适应不同应用场景。本文重点围绕Encoder-Decoder结构,列举一些以文本摘要生成或QA系统文本生成为实验场景的技术进展。
Seq2seq框架
2014年NLP界有两份重要的成果,Learning Phrase Representations using RNN Encoder–Decoder for Statistical machine Translation和Sequence to Sequence Learning with Neural Networks。虽然在Decoder的输入上有差别,但结构上两者都将Encoder-Decoder结构应用在翻译场景中,并由此开始,seq2seq框架在机器翻译,对话生成等领域中占据重要位置。另外,前者首次提出GRU结构,后者采用Beam Search改善预测结果,这些都成为如今seq2seq框架的基础技术元素。
随后,Bahdanau在Neural Machine Translation by Jointly Learning to Align and Translate中提出了融合attention和seq2seq结构的NMT模型结构,至此,由Encoder-Attention-Decoder组成的seq2seq框架正式形成。

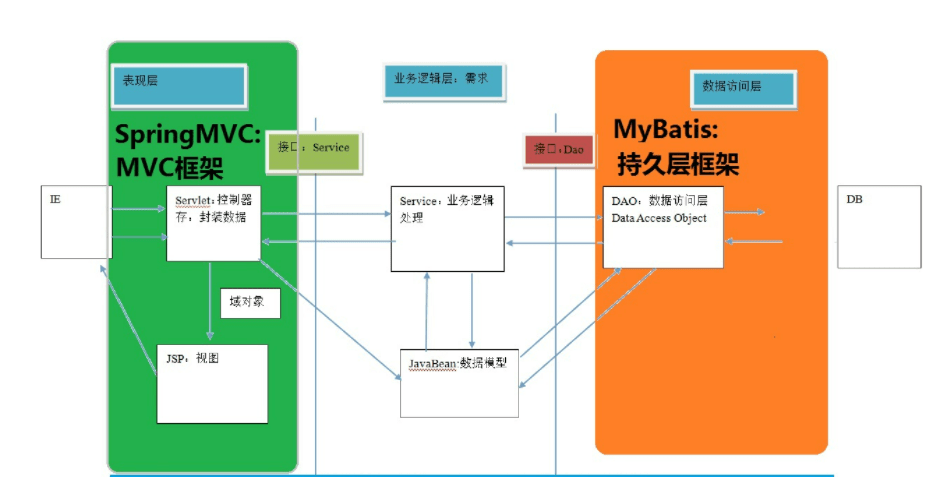
atention-seq2seq如上图所示,红色部分为Encoder模块,用于编码输入文本,计算状态值作为黄色的Decoder模块的初始状态;蓝色部分是Attention机制,结合Encoder模块和Decoder输入计算Context向量;最终Decoder部分结合Encoder的输入状态,Context向量,以及Decoder的历史输入,预测当前输出对应于词典的概率分布。
融合关键输入信息
了解机器翻译或生成任务的朋友都知道,无论Seq2seq模型多么复杂,最后都是用类似softmax的结构输出概率向量,然后映射到词典中某个词的的index,所以词表中没有的oov是无法被预测的。不同于机器翻译的是,摘要生成这类任务产生的摘要中很可能需要输入文本的信息,且通常会是某些关键词句,我们当然不希望因为词典中没有就丢失这些关键信息,因此需要想办法利用到输入文本中的信息。
- Pointer Networks
本文并没有解决上面提到的OOV问题,而是试图利用seq2seq处理特定的序列问题。我们已经提到,传统seq2seq结构的输出由类似词汇表的某个元素映射表确定,这样就无法应对词汇表随输入变动的情况,例如凸包问题,给定包含一组坐标点的序列,预测构成凸包的点集,此时词汇表的元素应该完全由输入构成,显然传统seq2seq无法处理。本文作者提出了一种精巧的,比传统attention-seq2seq更简单的pointer-net
作者的思路很简单,输出完全由输入决定,其实就是让输出指向某个输入,或者说就是预测输入的位置,这样最后预测概率向量的维数就是输入序列的长度,你再看attention的计算过程:

第一行结合了输入和输出的编码信息,第二行计算了输入序列的权重,这个权重不就是输入序列的概率向量么?没错就这么简单!对于找凸包,Delaunay三角剖分,旅行商问题等这类输出序列完全依赖输入序列的问题,pointer-net可以给出很精巧的解决方案。
此外,可以看到,虽然pointer-net没有直接解决OOV问题,但针对输出依赖输入的问题给出了一个很好的思路,下面的模型在考虑依赖输入OOV问题时多少都受到了pointer-net的启发。
- Incorporating Copying Mechanism in Sequence-to-Sequence Learning
本文提出的copy-net目标非常明确,就是构造一种copy机制解决上面提到的与输入相关的OOV问题。特别是摘要、对话生成这类问题,输入文本中一些词可以通过传统方式预测,另一部分词则可以直接复制在输出文本中,所以copy-net最终的词概率预测由两部分组成,generate-mode和copy-mode,分别用于传统的预测和copy词的预测。

上图展示了copy-net,左边是传统的attention-seq2seq结构,右边包含了copy-net全部改进思路。红框中展示了结合generate-mode和copy-mode的输出词预测,下面的蓝框包含了针对Decoder编码状态值的改进。
首先,generate-mode和copy-mode的输出概率如下:

V就是传统seq2seq的词汇表,X在这里是用于预测copy词的词典,可以看到无论P_c还是P_g,和传统seq2seq的形式都是一样的。区别在于词典,X上针对输入文本构造的,因此其中可能包含V中没有的词,所以copy-net解决上面提到的OOV问题的关键就是用这个词典预测copy词。
此外,蓝框中包含了复杂的状态更新机制。可以看到,S4的输入不仅包含Tony的词向量,还有一个Selective Read向量,这个是State Update机制计算得到的,这个状态更新机制对encoder后的输入矩阵M进行加权求和,意图是定位M中的某个位置,即输入序列中某个位置的元素,如下图公式所示。

完成状态更新后输入给generate-mode和copy-mode分别计算两个打分函数。

简单来说,copy-net的核心思路就是根据输入语料扩展原有词汇表,这样也就扩展了输出的概率向量的维数。不过要特别注意结合预测mode的实现,本质上最后仍然是预测一个维数更高的概率向量,所以最后需要合并两个维数不同的概率向量,即针对词典重合的部分的对齐处理,还是有点麻烦的,相比之下,下面介绍的pointer-generator模型就要简明许多。
- Get To The Point-Summarization with Pointer-Generator Networks
本文与copy-net的思路有诸多重合,但设计上比copy-net简单许多。核心同样是想办法让最终预测的概率向量涵盖输入文本中出现的OOV。

上图简单明了,以传统生成的绿色概率分布占P_gen的权重,与输入有关的蓝色概率分布占(1-P_gen)。与copy-net不同,这里直接用了pointer-net的思路,与输入有关的概率分布由attention直接生成。实现上,由于这个概率分布与输入序列直接相关,需要对每次feed的batch都扩展词汇表,其实就是在原有词汇表之后追加OOV对应的index,追加的部分,用于在最终合并概率分布时提供index,具体可参照作者提供的源码。
此外,本文还提出了一个特殊的coverage机制,用来处理生成词重复问题。

基本思路是,用之前attention矩阵的叠加作为覆盖向量c_t,参与当前attention的计算,从而让当前的attention尽量避免出现重复的位置。此外可以在计算损失函数时也加入覆盖向量c_t缓解重复问题。

融合知识特征
关于融合输入元素的尝试进一步启发了NLPer,对于这类学习文本向量表示的模型,利用实体特征和外部知识图谱直觉上就有点靠谱,既然输入序列中的词可以利用,那么充分利用实体信息知识图谱等,为文本添加额外的知识特征自然也是可能的。
- Generating Natural Answers by Incorporating Copying and Retrieving Mechanisms in Sequence-to-Sequence Learning
本文来自阿里团队,以问答系统为实验场景,在copynet的基础上加入知识检索模块共同配合回复生成。模型结构图如下:

其实无论模型结构还是文章结构,本文和那篇copynet都非常相近,相当于增加了预测知识的copy-mode机制,因此这里不再介绍本文的细节。不过从文中与copynet对比的实验结果来看,引入知识检索带来的提升非常可观,虽然实验仅用在对话生成领域,不过在其他文本生成领域引入知识特征也同样值得尝试,下一篇同样来自阿里团队的工作,将融合了知识特征的seq2seq结构用于网购商品的摘要生成。
- Multi-Source Pointer Network for Product Title Summarization
网购商品的摘要生成需要更大程度保留关键信息,同时避免无关内容。本文的结构很像引入知识特征的pointer-generator,利用pointer的思想从输入文本中提取关键词,这里的输入文本是商品的标题,确保信息相关;引入知识特征则是为了更大程度的产生关键信息。

从上图的结构中可以看到,文中提出的MS-Pointer结构有两个输入,商品标题作为传统Encoder输入,背景知识作为额外的输入文本,两种输入的处理方式相同,encoding后与Decoder的输入分别计算出两个attention,然后按照pointer-generator的思路结合两种分布,只不过这里结合的是传统词表的概率分布与背景知识特征的概率分布。
- Learning to Select Knowledge for Response Generation in Dialog Systems
上面两篇文章分别对copy-net和pointer-generator做知识特征融合,结构上没有很大的改变,基于前者实现也是相对方便的。本文则更侧重于知识特征,强调利用后验知识分布优化对话生成。

乍一看比上面的结构都复杂,但其实每个部分都有明确的目标,最上面sourceX到decode的部分就是传统的attention-seq2seq,这里重点介绍下面关于知识特征的融合利用。
首先,用单独的Encoder模块编码知识和目标输出(训练时),然后通过X,Y计算知识K的先验和后验概率分布,并通过KL散度度量两个概率分布的距离,这里不难理解,先验分布和后验分布相差极小就意味着可以用先验分布采样知识(预测时后验分布未知),并用于生成目标回复Y。第二部分中,通过后验(预测时先验代替)分布采样出与对话相关的知识作为额外的知识特征,与Decoder模块的输入一起编码,再和被encoding的sourceX一起预测下一个词。此外,训练的损失函数包含KL散度,NLL损失和BOW损失,第三部分就是用BOW损失考量被采样出的知识(图中的k2)与目标输出文本相关的概率。
总结一下,本文仍然是seq2seq框架,关键就是用两个计算损失优化模型采样知识的能力,然后将知识作为额外特征参与Encoder-Decoder编码。相比于模型结构,笔者更关注数据中的知识形式,本文的源码和数据会在发表后开放,项目地址就在文中,各位感兴趣可以持续关注。
卷积结构上的新尝试
2017年有两篇基于机器翻译任务的工作摆脱了RNN结构,采用了CNN和Transformer,一定程度上证明了非RNN结构在NLP任务上的可行性。Facebook的这篇Convolutional Sequence to Sequence Learning提出了基于Attention-Seq2seq框架的Convs2s结构,用CNN做编解码单元,通过学习位置向量弥补CNN不具备的序列特征捕捉特性,并借助残差结构,GLU等技巧让网络可以堆叠的足够深,从而让CNN也能捕捉长距离文本特征,另外CNN的并行能力远超RNN,因此该结构理论上似乎可以更节省时间,本节将介绍两篇基于Convs2s结构的工作,第一篇融合了主题模型作为额外的特征,第二篇结合了强化学习的方式,两者虽基于Convs2s结构,但对其他结构同样有启发性。
- Don’t Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization
本文的结构和Convs2s几乎完全一致,其创新点就在于网络输入融合了传统的文本embedding和主题向量,如下图所示:

个人认为,融合主题模型的思路很适合文本摘要类任务,笔者用pointer-generator实验时就发现,即便模型可以输出贴近自然语言的结果,也可以包含一些特殊词,但丢失原文关键信息的现象仍然非常明显,特别是训练语料不充分的情况下。结合知识特征自然是一种合理的思路,但构建知识图谱或类似的结构化知识数据并不是一件简单的事,相比之下主题模型就更为容易应用了。此外本文融合主题的方式非常直接,并不依赖网络结构,很容易应用于其他模型结构。
- A Reinforced Topic-Aware Convolutional Sequence-to-Sequence Model for Abstractive Text Summarization
本文结构与上文相近,不过在融合主题信息的方式上有很大变化,此外引入RL方式来解决传统损失函数带来的问题,思路也非常值得借鉴。

由上图可以看出,本文的主题信息不再和输入文本的embedding求和,而是先单独通过卷积编码,再和decoder的输入部分共同参与attention计算,通过两边的attention相加来融合文本embedding和主题信息;此外,还有一个概率生成模块(biased probability generation)负责进一步控制融合。
损失函数部分用到了强化学习中的SCST(self-critical sequence training)。作者提到,传统teacher forcing算法目标是最小化每一步的极大似然损失,然而考虑到ROUGE这样衡量句子级准确度的验证算法,由于exposure bias的问题,该目标往往会得到次优解(训练时每次都通过ground-true预测当前步,预测时没有ground-true);此外,摘要具有灵活性,而最小化极大似然损失的优化目标会迫使模型仅把参考的摘要作为正确答案,其他语意上相似的答案会被认为是错误答案。为了解决原有优化目标带来的问题,作者提出用SCST直接最大化不可微的ROUGE,训练时根据输入产生两个输出,一个用传统概率最大化生成,另一个从分布中采样得到,计算两个输出序列的rouge分数作为reward,这样在训练阶段,SCST会让模型参考实际的分布,并迫使模型生成rouge分数更高的序列。
Transformer时代
承接上一节,Transformer完全抛弃了CNN与RNN,设计了并行能力同样强的self-attention,与FFN,残差结构等共同组成一个Transformer模块,类似CNN可以堆叠多层且较RNN更节省时间。不过,Transformer和Convs2s在机器翻译任务上的表现差异并不大,加之Attention is all you need这样的文章标题,不少人在当时一度认为这又是一个拼模型刷分的水文,直到2018年GPT和BERT的诞生,深层Transformer堆叠+海量无监督语料预训练的模式受到几乎所有从业者的关注。本节介绍的是MSRA近期发表的MASS,作者通过修改BERT的mask方式实现Seq2seq框架下BERT预训练的文本生成模型。
- MASS: Masked Sequence to Sequence Pre-training for Language Generation

BERT本身是以学习表示为目标,或者说是NLU方面的探索,随机MASK作为预训练任务被证明效果突出,然而会存在pretraining和fine-tuning数据不一致的问题,如果你想把BERT拼在Encoder端和Decoder端,就要考虑改变BERT的预训练方式。MASS略微修改了BERT的mask方式,在Encoder端连续mask一个子序列,让Decoder用前i-1个词预测第i个,就这样把BERT套进Seq2seq框架,一起pretraining即可。
总结
本文重点介绍了基于Seq2seq框架的文本生成类模型,对于机器翻译任务,传统的attention-seq2seq结构就能获得不错的效果,相比于不同的模型结构,充分的训练数据似乎更为关键。而对于文本摘要,对话生成这类任务,序列中更需要包含主题,关键实体等特殊信息元,因而融合主题、输入文本、知识特征的策略很可能会带来更多收益。不过,文本生成类任务仍处于初级阶段,复杂花哨的结构也许很难达到可观的效果。因此笔者建议,即便是文本摘要这类任务,仍不妨先试试受众广泛的开源实现,诸如gnmt、fairseq、tensor2tensor等。
关于本文提到的一些trick,copy机制的实现有些复杂,并且不少开源项目的copy实现是存在问题的,pointer-generator的效果更好,且实现上更容易,当然,主题和知识特征的融合也是值得尝试的技巧。最后,本文没有过多涉及的强化学习和对抗网络,在文本生成方向上有不少值得借鉴的工作,也可以作为文本生成任务的一个方向考虑。