作者:吴陈旺、王希廷、连德富
为了深入了解大模型的科学原理并确保其安全,可解释变得日益重要。解释大模型带来了很多独特挑战:(1)大模型参数特别多,怎么尽可能确保解释速度?(2)大模型涉及的样本特别多,如何让用户尽可能少看一些样本的解释也能了解大模型的全貌?这两个问题都指向了对大模型解释效率的要求,而我们希望通过新的范式,为构建大模型高效解释之路提供一个思路。
我们的高效新范式是通过从因果角度重新审视模型来获得的。我们首先从因果的视角重新审视知名可解释方法(比如 LIME、Shapley Value 等),发现他们的解释得分对应于因果推理中的因果效应(treatment effect),明确构建了这些方法和因果的联系。这不仅让我们可以统一对比这些方法的优缺点,还可以分析他们的因果图,发现其中导致不够高效的原因:(1)他们的解释需要特别多次对大模型的扰动才能获得,解释速度慢;(2)他们的解释不具备泛化性:对相似的样本,其解释可能剧烈变化,导致用户无法通过看少量样本解释得到本质的、对其他样本也适用的本质原因。
基于这个发现,我们提出了新的因果图,并遵循重要的因果原则,提出了因果启发的模型解释框架(Causality Inspired Framework for Model Interpretation, CIMI)来设计解释器的训练目标和理想属性。实验结果表明,CIMI 提供了更忠诚和可泛化的解释,同时具有更高的采样效率,使其特别适合更大的预训练模型。
通过阅读本文你可以了解到:
现有知名可解释方法和因果之间的联系是什么?如何从统一的因果视角去对比它们的优缺点?
更好、更高效的因果图是什么?对应的可解释方法是什么?
本文同时也还有不少需要改进之处,比如我们目前都分析的是分类模型而不是文本生成模型;我们主要在常规大小的预训练模型上验证了解释效率,对于很大规模模型的测试还在进一步实验中;我们的框架尽管通用,但是具体采用方法目前需要模型最后一层 embedding,对于不公开 embedding 的模型如何高效分析还不明确。这些问题希望在后续和大家探讨中共同解决。

论文地址:
https://dl.acm.org/doi/pdf/10.1145/3580305.3599240
开源地址:
https://Github.com/Daftstone/CIMI
研究背景
深度学习在医疗保障、金融预测分析、故障检测等诸多领域发挥着关键作用。然而,深度模型大多是人类无法理解的黑盒,这种不透明性可能产生严重后果,尤其在高风险决策中。例如,基于深度学习的污染模型声称高污染空气对人类健康没有威胁 [1]。不完美的模型并非毫无意义,如果可以解释模型做出特定决策的原因,就可能有效地降低和避免模型错误的风险。另外,公开透明的模型也有助于发现模型中潜在的错误(比如,推理逻辑与领域知识不符),从而进一步改进模型 [2]。因此,可解释人工智能(eXplAInable Artificial Intelligence, XAI)的研究受到了越来越多的关注。
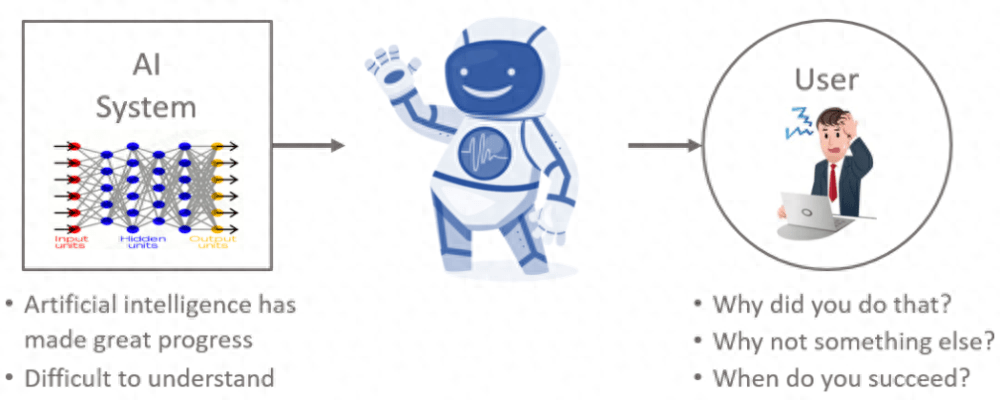
图 1. 深度学习模型的不透明性。
可解释学习中一个基本问题是:解释是否揭示了模型行为的重要根本原因,还是仅仅是虚假的相关性?无法区分相关性和因果关系会导致决策者做出错误的解释。在人机交互方面的研究 [3] 进一步突出了因果关系的重要性,其中广泛的用户研究表明,在可解释人工智能中,因果关系增加了用户信任,并有助于评估解释的质量。这一结果呼应了认知科学中的主要理论,即人类使用因果关系来构建对世界的心理模型 [4]。
另外,可解释人工智能遵循基本的因果性假设,为因果研究提供了理想的环境,而这些假设通常在其他情况下是难以验证的。例如,在可解释研究中,我们可以轻易地获得一组变量(比如,一个句子的所有单词的组合),这些变量构成了模型预测的所有可能原因的完整集合,这确保满足了因果充分性假设 [5]。此外,黑盒模型可以轻松进行干预,这允许直接执行关键的 do 操作(do-operator)。例如,因果研究的环境通常是一次性的,一个人吃过药了就无法让他不吃药,如果需要建模吃药和康复的因果关系,就需要仔细对混杂因素建模,并使用后门或者前门调整等技术将因果估计转化为统计估计,并仅基于观测数据计算该统计估计。而在可解释中,干预变得尤为简单。这是因为要解释的模型所处的环境非常清楚,允许直接对任何特征进行 do 操作并查看模型预测的变化,并且这一操作可以重复操作。
因果视角的关键问题
由于因果在可解释研究中的重要性和适用性,已经引起了越来越多的关注。多种解释方法,如 LIME [6],Shapley Value [7] 以及 CXPlain [8],利用干预 (例如对输入数据扰动) 等因果分析技术提供更忠诚的黑盒模型解释。尽管如此,仍然缺乏一个正式统一的因果视角,并且一些关键研究问题仍然具有挑战性,例如:
RQ1. 现有解释方法和因果的关系:现有的解释方法能否在一个因果框架内进行构建?如果可以的话,所采用的因果模型是什么,并且它们之间有什么区别?
RQ2. 因果推理在可解释中的挑战:在利用因果推理进行模型解释方面,主要的挑战是什么?通过解决这些挑战,我们可能会获得哪些好处?
RQ3. 如何利用因果推理改进可解释方法:如何改进因果模型以解决这些挑战?
在该工作中,我们旨在通过研究这些问题来弥合因果推理与可解释性之间的差距。
从因果角度重新审视可解释(RQ1)
通过从因果的角度重新审视现有的方法,我们可以证明许多经典的基于扰动的可解释方法,如 LIME、Shapley Value 以及 CXPlain,实际上计算的是(平均)因果效应。因果效应构成了这些特征的解释得分,旨在揭示模型预测中每个特征被纳入解释的程度。
另外,他们的因果图与图 2(左)相对应。其中,对 E 的治疗(treatment)对应于对一个或一组特定特征的扰动。C 是上下文特征,表示在改变 E 后保持不变的特征。

图 2. 左:现有方法的因果图,其中解释 E 和上下文 C 都是影响模型预测 的因素;右:从统一的因果视角对现有可解释方法的比较。
尽管这三种方法都可以使用图 2(左)中的因果图进行总结,但它们也会存在些许差异,如图 2(右)所示。我们将展示该统一的视角如何轻松地比较每个方法的优缺点:

因果推理应用于可解释的挑战(RQ2)
根据上一节的观察结果,我们能够总结将因果推理应用于模型解释的核心挑战。虽然解释方法很容易计算个体因果效应,比如,当一个输入特征改变时,模型的预测结果发生了多大的变化,但核心挑战是如何有效地发现可以从大量特征和数据点推广到不同实例的突出共同原因。要解决这个问题,需要保证解释是:

图 3:解释增强用户信任的例子:病理检测器。


图 4:(左). 现有方法的因果图,其中解释不是模型预测的唯一原因;(中). 候选因果图,其中解释对模型预测是因果充分的,但不是泛化的;(右). 我们的选择,其中解释是泛化且是的唯一原因。可观测变量用蓝色阴影表示。
利用因果改进可解释(RQ3)
基于上一节的讨论,我们希望根据选择的因果图提升解释质量(因果充分和可泛化)。但由于两个重要的因果变量 E 和 U 是不可观察的,直接在图 4 (右) 的因果图中重构因果机制是不切实际的。考虑到因果变量需要遵循明确的原则,我们使用以下两个因果推理中的重要原则来设计因果变量应满足的基本属性:

基于选择的因果图以及这两个因果原则,我们设计了一个因果启发的模型解释框架,CIMI。CIMI 包含三个模块:因果充分模块、因果干预模块以及因果先验模块,以确保提取的解释满足这两个原则所需的基本属性。

图 5. 左:因果充分示意图;中:因果干预示意图;右:解释器的结构设计。




实验分析
我们选择了 BERT 和 RoBERTa 作为待解释的黑盒模型,在 Clickbait、Hate、Yelp 以及 IMDB 数据集来评估生成解释的质量。具体的统计数据如图 6 所示。
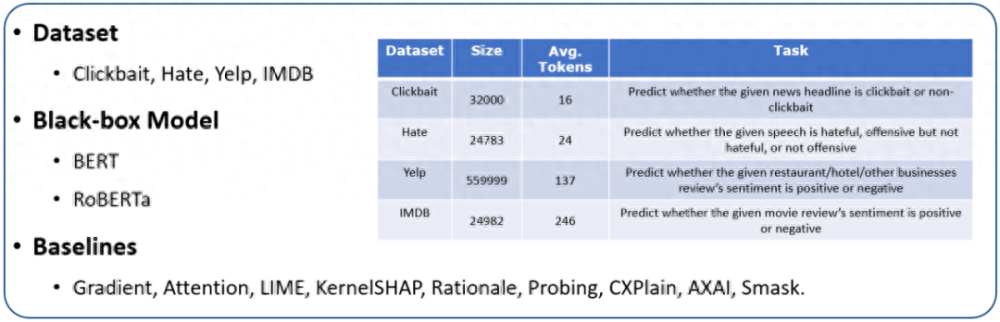
图 6. 实验设置。
我们将对解释的忠诚性、泛化性、采样效率以及可用性进行评估。
1. 忠诚性评估:我们使用三个忠诚度指标来评估生成解释的因果充分性,分别为 DFFOT(决策翻转的分词比例)、COMP(必要性)、SUFF(充分性)。这些指标的细节以及我们的实验结果如图 7 所示。可以看出提出的方法在各种数据集上是有竞争力的。特别地,随着数据集的复杂度越来越高(CLickbaitIMDB),相较于基线方法的提升效果更加明显。例如,在 Clickbait 上,和最好的基线方法比较,关于 DFFOT 的性能提升为 4.2%,而在 IMDB 上,相应的性能提升为 54.3%。这种良好的性质突出了我们的算法具有更好的可扩展性。
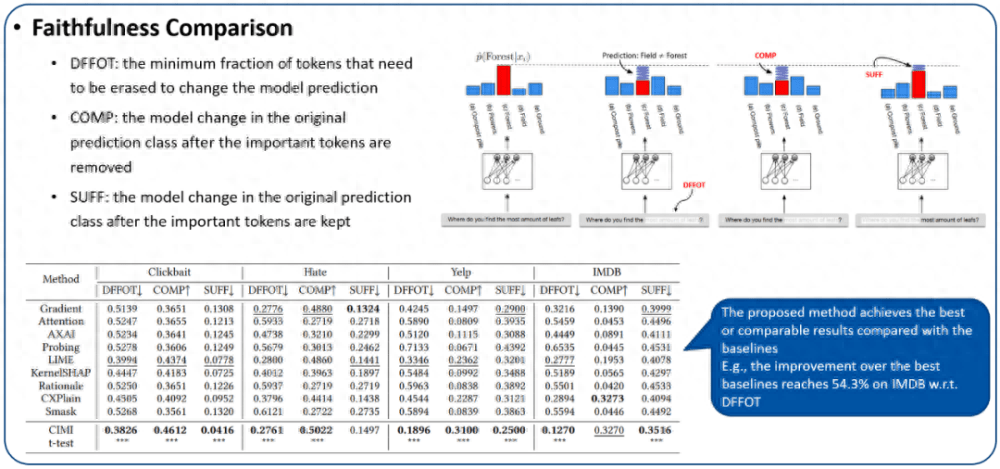
图 7. 解释的忠诚性评估。
2. 泛化性评估:我们使用 AvgSen(平均敏感度)来评估生成解释的泛化性。不可否认,对于 AvgSen 来说,解释中包含的一些重要的 token(解释)可能会被替换,但概率很低,尤其是在分词数量较多的 Yelp 和 IMDB 中。实验结果如图 8 所示。可以看到,在四个数据集中,扰动前后的 Top-10 重要分词中至少有 8 个是一致的,这对于基线方法是难以做到的。这表明提出的方法具有捕获不变泛化特征的能力,这种泛化能力有助于避免对相似实例的重复解释的耗时成本,同时这种稳定的解释也有助于增强人们的信任。
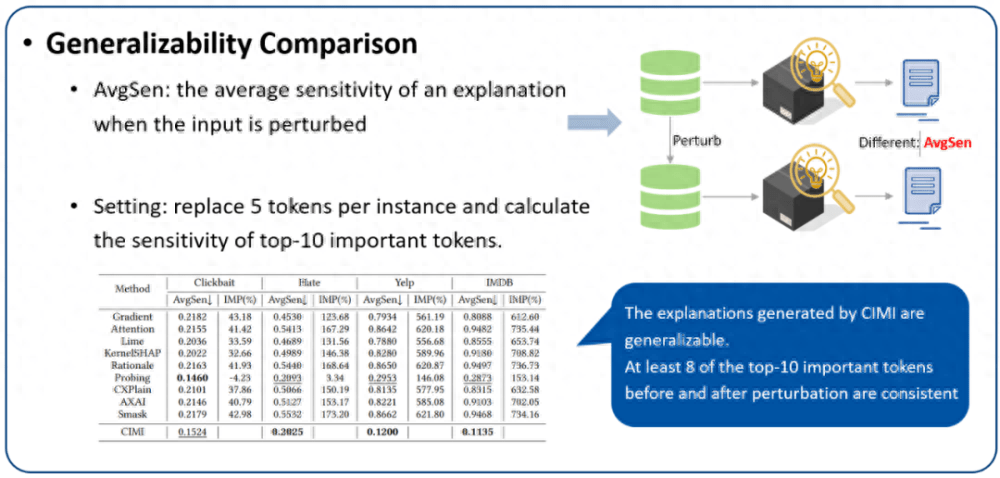
图 8. 解释的泛化性评估。
3. 采样效率(即解释速度)评估:图 9 展示了在相同采样次数(模型前向传播次数)下,各种基于扰动方法的性能比较。首先,CXPlain 的单特征扰动的解释机制使每个样本 x 的扰动次数最多为 |x| 次,因此在小数据集上表现出了较高的效率。其次,所提出方法在四个数据集中都显示出显著的竞争力,特别是在 Hate 上,只需要 3 个采样次数就可以超过具有 100 个采样次数的基线。这得益于神经网络在因果原则约束下的泛化能力,从大量的数据点中总结出推广到不同的实例的解释,最终提高效率。在大模型高速发展的时代,由于模型越来越大,要解释的数据点也越来越多,这种高效的采样对于解释方法显得越来越重要。
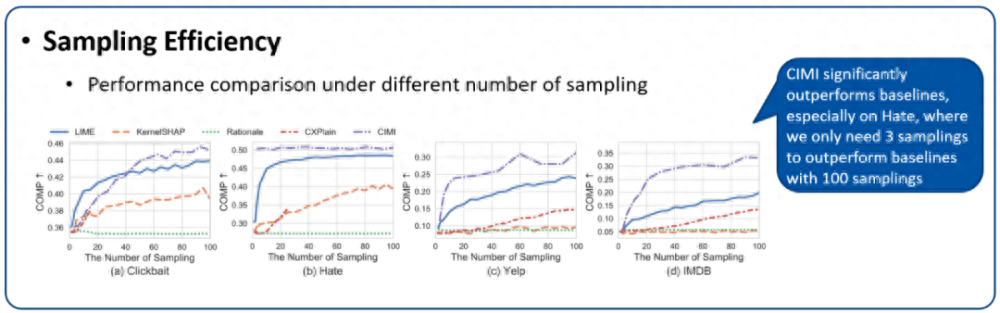
图 9. 解释方法的采样效率评估。
4. 可用性评估:解释除了让我们更好地理解模型,还有帮助调试模型。有噪声的数据收集可能会导致模型在训练过程中学习到错误的相关性。为此,本节分析了各种解释方法在删除捷径特征(shortcut)的能力。我们使用 20 newsgroups 的一个子集分类 “基督教” 和 “无神论”。选择该数据集的原因是训练集中有很多捷径特征,但测试集是干净的。例如,在训练集中出现单词 “posting” 的实例中,99% 的实例都属于 “无神论” 的类别。
为了测试解释方法是否可以帮助检测捷径特征,我们首先在有噪声的训练集上训练 BERT 模型。然后,我们获得不同方法的解释,如果解释中的分词没有出现在干净的测试集中,则将其视为潜在的捷径特征。然后,在删除捷径特征后重新训练分类模型。评估各种解释方法识别捷径特征的指标是移除潜在捷径特征后重训练模型的性能 (更好的分类性能意味着找到的捷径特征更准确)。结果如图 10 所示。首先,LIME 和提出的方法都能有效去除捷径,提高模型性能。其次,CIMI 对模型性能的改进更加明显,这表明其检测的捷径特征更为准确。
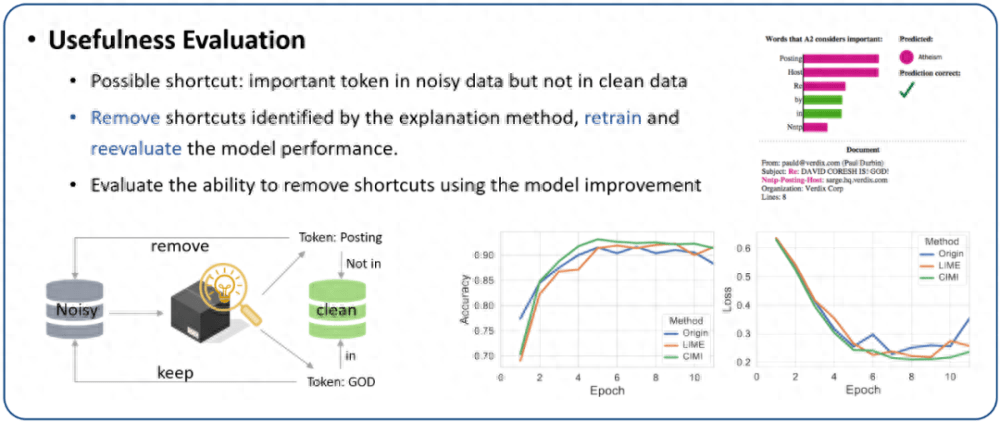
图 10. 解释方法的可用性评估。
总结
本文从因果推理的角度重新解读了一些经典的可解释方法,发现他们的解释得分对应于因果推理中的因果效应。通过在这个统一的因果视角分析它们的利弊,揭示了利用因果推理进行解释的主要挑战:因果充分性和泛化性。最后,基于合适的因果图和重要的因果原则,设计了神经解释器的训练目标和理想属性,并提出了一种高效的解决方案 CIMI。通过广泛的实验,证明了所提方法在解释的因果充分性、泛化性以及采样效率方面的优越性,并探索了解释方法帮助模型调试的潜力。
参考文献
[1] Michael McGough. 2018. How bad is Sacramento’s air, exactly? google results Appear at odds with reality, some say. Sacramento Bee 7 (2018).
[2] G Xu, TD Duong, Q Li, S Liu, and X Wang. 2020. Causality Learning: A New Perspective for Interpretable machine Learning. IEEE Intelligent Informatics Bulletin (2020).
[3] Jonathan G Richens, Ciarán M Lee, and Saurabh Johri. 2020. Improving the accuracy of medical diagnosis with causal machine learning. Nature communications 11, 1 (2020), 3923.
[4] Steven Sloman. 2005. Causal models: How people think about the world and its alternatives. Oxford University Press.
[5] Brady Neal. 2020. Introduction to causal inference from a machine learning perspective. Course Lecture Notes (draft) (2020).
[6] Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. 2016. "Why should i tRust you?" Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. 1135–1144.
[7] Scott M Lundberg and Su-In Lee. 2017. A unified approach to interpreting model predictions. Advances in neural information processing systems 30 (2017).
[8] Yuzuru Okajima and Kunihiko Sadamasa. 2019. Deep neural.NETworks constrained by decision rules. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33. 2496–2505.
[9] Clive WJ Granger. 1969. Investigating causal relations by econometric models and cross-spectral methods. Econometrica: journal of the Econometric Society (1969), 424–438.
[10] Jonas Peters, Dominik Janzing, and Bernhard Schölkopf. 2017. Elements of causal inference: foundations and learning algorithms. The MIT Press.
[11] Philippe Brouillard, Sébastien Lachapelle, Alexandre Lacoste, Simon LacosteJulien, and Alexandre Drouin. 2020. Differentiable causal discovery from interventional data. Advances in Neural Information Processing Systems 33 (2020), 21865–21877.