
作者:Chip Huyen
翻译:阿法兔
来源链接:https://huyenchip.com/2023/08/16/llm-research-open-challenges.html
让大语言模型变得更完善这个目标,是我一生中,第一次见到这么多的聪明人,同时在为一个共同目标而努力。在同众多业界和学术界人士交流后,我注意到出现了十大研究方向。目前受到关注最多的两个方向是Hallucinations(输出幻觉) 和 Context Learning。
而对我自己来说,最感兴趣的是下面列出的第 3 个方向(Multimodality多模态数据模式)、第 5 个方向(New architecture 新架构)和第 6 个方向(GPU alternatives开发GPU替代的解决方案)
LLM 研究的十大公开挑战1. 减少和评估幻觉减少并评估输出输出(虚构信息)
优化上下文长度和上下文构建
融合其他数据形式
提升语言模型的速度和成本效益
设计新的模型架构
开发替代GPU的解决方案
提升代理(人工智能)的可用性
改进从人类偏好中学习的能力
提高聊天界面的效率
构建用于非英语语言的语言模型
输出环境是一个已经被大量讨论过的话题,所以这里我会长话短说。当人工智能模型胡编乱造时,就会产生幻觉。对于许多创意用例来说,幻觉属于功能的一种。然而,对于大多数应用场景来说,幻觉属于一种错误。最近,我与 Dropbox、LangchAIn、Elastics 和 Anthropic 的专家共同参加了一个关于 LLM 的专题讨论会,在他们看来,企业在实际生产中,应用 LLM 需要克服的首要障碍就是幻觉输出。
降低模型的幻觉输出和制定评估幻觉输出的指标,是一个蓬勃发展的研究课题,目前很多初创公司都在关注这个问题。还有一些技巧可以减少幻觉输出的概率,例如在提示词中添加更多上下文、CoT、自洽性,或者特定要求模型的响应简洁明了。
下面是关于幻觉输出的系列论文和参考资料:
Survey of Hallucination in Natural Language Generation(Ji et al., 2022)
How Language Model Hallucinations Can Snowball(Zhang et al., 2023)
A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity(Bang et al., 2023)
Contrastive Learning Reduces Hallucination in Conversations(Sun et al., 2022)
Self-Consistency Improves Chain of Thought Reasoning in Language Models(Wang et al., 2022)
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models(Manakul et al., 2023)
A simple example of fact-checking and hallucination by NVIDIA’s NeMo-Guardrails
2.优化上下文长度和上下文构建
绝大部分问题都需要上下文。例如,如果我们问ChatGPT:“哪家越南餐厅最好?”所需的上下文将是“这个餐厅的限定范围到底在哪里?”,因为越南本土最好吃的餐厅与美国的最好吃的越南餐厅,这个问题的范围是不同的。
根据下面这篇很酷的论文《 SITUATEDQA: Incorporating Extra-Linguistic Contexts into QA 》(Zhang&Choi,2021),有相当一部分信息搜索问题的答案与上下文有关,例如,在Natural Questions NQ-Open 数据集中大约占 16.5%。
(NQ-Open:https://ai.google.com/research/NaturalQuestions)
我个人认为,在企业实际遇到的案例中,这一比例会更高。例如,假设一家公司为客户支持建立了一个聊天机器人,要让这个聊天机器人回答客户关于任何产品的任何问题,所需的上下文很可能是该客户的历史或该产品的信息。由于语言模型会从提供给它的上下文中 "学习",因此这一过程也被称为上下文学习。
图片客户支持查询所需的上下文
Context length 对于RAG(检索增强生成)非常重要,而RAG已成为大语言模型行业应用场景的主要模式。具体来说,检索增强生成主要分为两个阶段:
第 1 阶段:分块(也称为编制索引)chunking (also known as indexing)
收集LLM使用的所有文档,将这些文档分成可以喂入大于模型,以生成嵌入的块,并将这些嵌入存储在向量数据库中。
第2阶段:查询
当用户发送查询时,如 "我的保险单是否能够支付某种药物 X",大语言模型会将此查询转换为embedding,我们称之为 QUERY_EMBEDDING。向量数据库,会获取embedding与 QUERY_EMBEDDING 最相似的块。
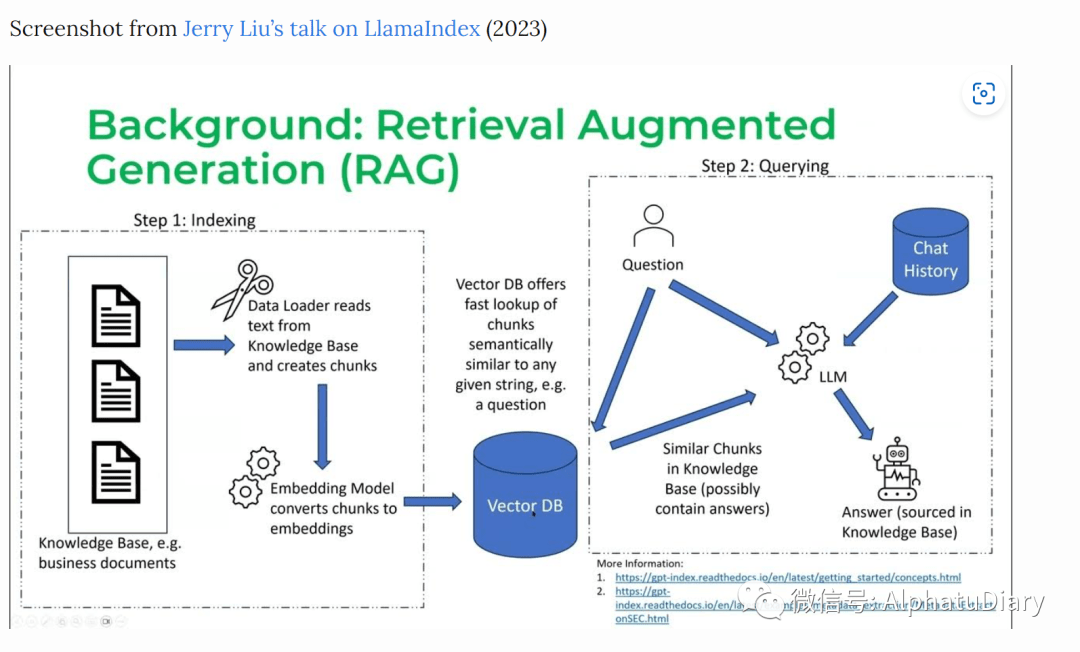
上下文长度越长,我们就能在上下文中squeeze越多的chunks 。模型获取的信息越多,它的输出和回应质量就会越高,是这样的吗?
并非总是如此。模型能用多少上下文,和模型使用上下文的效率如何,是两个不同的问题。在努力增加模型上下文长度的同时,我们也在努力提高上下文的效率。有人称之为 "提示工程prompt engineering "或 "prompt construction"。例如,最近有一篇论文谈到了模型如何更好地理解索引开头和结尾,而不仅是中间的信息——Lost in the Middle: How Language Models Use Long Contexts (Liu et al., 2023).
3. 其他数据模式融入(多模态)
在我看来,多模态是非常强大的,但是它也同样被低估了。这里解释一下多模态的应用原因:
首先,许多具体应用场景都需要多模态数据,尤其是在医疗保健、机器人、电子商务、零售、游戏、娱乐等混合数据模态的行业。举例来说:
医疗检测通常需要文本(如医生笔记、患者问卷)和图像(如 CT、X 光片、核磁共振扫描片)。
产品的Metadata通常包含图片、视频、描述,甚至表格数据(如生产日期、重量、颜色),因为从需求角度,您可能会需要根据用户的评论或产品照片,自动填补缺失的产品信息,或者希望让用户能够使用形状或颜色等视觉信息,进行产品搜索。
其次,多模态有望大幅提升模型性能。一个既能理解文本又能理解图像的模型,难道不应该比单一能理解文本的模型表现更好吗?基于文本的模型,需要大量文本,以至于我们担心很快就会用完互联网数据来训练基于文本的模型。一旦文本耗尽,我们就需要利用其他数据模式。
让我特别兴奋的一个使用案例是,多模态技术可以让视障人士浏览互联网和浏览现实世界。
下面是关于多模态相关的系列论文和参考资料:
[CLIP] Learning Transferable Visual Models From Natural Language Supervision(OpenAI, 2021)
Flamingo: a Visual Language Model for Few-Shot Learning(DeepMind, 2022)
BLIP-2: BootstrApping Language-Image Pre-training with Frozen Image Encoders and Large Language Models(Salesforce, 2023)
KOSMOS-1: Language Is Not All You Need: Aligning Perception with Language Models(Microsoft, 2023)
PaLM-E: An embodied multimodal language model(Google, 2023)
LLaVA: Visual Instruction Tuning(Liu et al., 2023)
NeVA: NeMo Vision and Language Assistant (NVIDIA, 2023)
4. 让 LLM 更快、成本更低
当GPT-3.5在2022年11月底首次发布时,很多人对在生产中使用它的延迟和成本表示担忧。然而,自那时以来,延迟/成本分析已经迅速发生了变化。在不到半年的时间里,社区找到了一种方法,可以创建一个性能与GPT-3.5非常接近的模型,但所需的内存占用仅为GPT-3.5的2%左右。
这里的启示是:如果你创造出足够优秀的东西,人们会找到一种方法让它变得快速且经济高效。
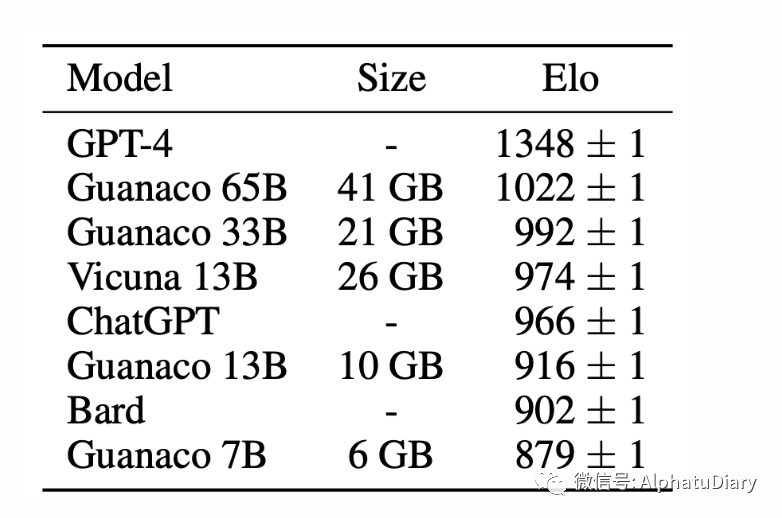
以下是《Guanaco 7B》的性能数据,与ChatGPT GPT-3.5和GPT-4的性能进行了比较,根据《Guanco》论文中的报告。请注意:总体而言,下列关于性能的比较,离完美还差很远,并且,对LLM的评估非常非常困难。
Guanaco 7B 与 ChatGPT GPT-3.5 和 GPT-4 的性能比较:
四年前,当我开始为《设计机器学习系统》一书撰写后来成为 "模型压缩 "部分的笔记时,我写了关于模型优化/压缩的四种主要技术:
Quantization:迄今为止最通用的模型优化方法。量化通过使用较少的位数来表示模型的参数来减小模型的大小,例如,可以使用16位甚至4位来表示浮点数,而不是使用32位。5.设计一种新的模型架构Knowledge distillation:一种通过训练小模型来模仿大型模型或模型集合的方法。
Low-rank factorization:这里的关键思路是用低维张量代替高维张量,以减少参数数量。例如,可以将 3x3 张量分解为 3x1 和 1x3 张量的乘积,这样就不再需要 9 个参数,而只需要 6 个参数。
Pruning
所有上述四种技术在今天仍然适用和流行。Alpaca 采用Knowledge distillation进行训练。QLoRA 结合使用了Low-rank factorization和quantization。
自 2012 年的 Ale.NET 以来,我们看到了许多架构的兴衰,包括 LSTM、seq2seq 等。与这些相比,Transformer 的影响力,令人难以置信。自 2017 年以来,Transformer 就一直存在,而这种架构还能流行多久,还是个未解之谜。
开发一种新架构来超越 Transformer 并不容易。Transformer 在过去 6 年中进行了大量优化,而这种新架构,必须在人们当前关注的硬件,以当前关心的规模运行。
注意:谷歌最初设计 Transformer 是为了在 TPU 上快速运行,后来才在 GPU 上进行了优化。
2021 年,Chris Ré's lab的 S4 引起了广泛关注,详见《Efficiently Modeling Long Sequences with Structured State Spaces 》(Gu et al., 2021))。Chris Ré's lab仍在大力开发新架构,最近与初创公司 Together 合作开发的架构 Monarch Mixer(Fu ,2023 年)就是其中之一。
他们的主要思路是,对于现有的 Transformer 架构,注意力的复杂度是序列长度的二次方,而 MLP 的复杂度是模型维度的二次方。具有次二次方复杂度的架构将更加高效。
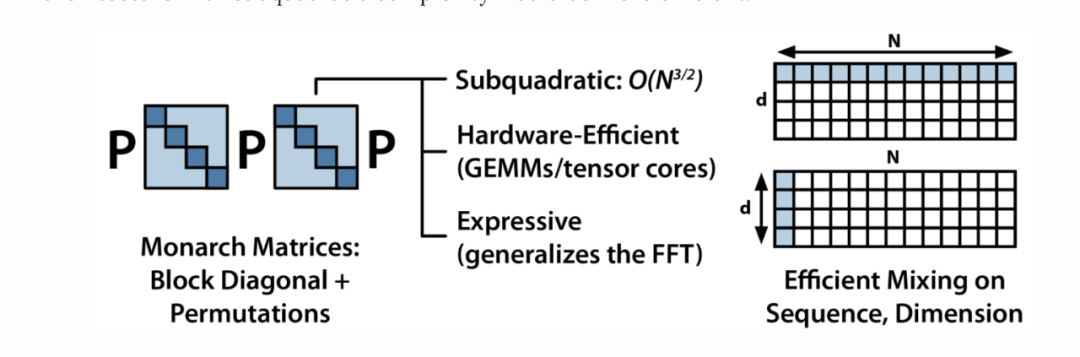
Monarch Mixer
6. 开发 GPU 替代方案
自2012年的AlexNet以来,GPU一直是深度学习的主导硬件。实际上,AlexNet受欢迎的一个普遍认可的原因之一是它是首篇成功使用GPU来训练神经网络的论文。在GPU出现之前,如果想要以AlexNet的规模训练模型,需要使用数千个CPU,就像谷歌在AlexNet之前几个月发布的那款。与数千个CPU相比,几块GPU对于博士生和研究人员来说更加容易得到,从而引发了深度学习研究的繁荣。
在过去的十年里,许多公司,包括大型企业和创业公司,都试图为人工智能创建新的硬件。最值得注意的尝试包括谷歌的TPU、Graphcore的IPU(IPU的进展如何?)以及Cerebras。SambaNova筹集了超过十亿美元来开发新的AI芯片,但似乎已转向成为一个生成式AI平台。
有一段时间,人们对量子计算抱有很大的期望,其中关键参与者包括:
IBM的QPU谷歌的量子计算机在今年早些时候在《自然》杂志上报道了量子误差减少的重大里程碑。其量子虚拟机可以通过Google Colab公开访问。
研究实验室,如麻省理工学院量子工程中心、马克斯·普朗克量子光学研究所、芝加哥量子交流中心、奥克里奇国家实验室等。
另一个同样令人兴奋的方向是光子芯片(photonic chips)。我对这个领域知之尚浅, 所以,如果有错误,请纠正我。现有芯片使用电力来传输数据,这消耗大量的能量并且产生延迟。而光子芯片使用光子来传输数据,利用光速进行更快、更高效的计算。在这个领域,各种初创公司已经融资数亿美元,包括Lightmatter(2.7亿美元)、Ayar Labs(2.2亿美元)、Lightelligence(2亿美元以上)和Luminous Computing(1.15亿美元)。
以下是光子矩阵计算三种主要方法的进展时间线,摘自论文《Photonic matrix multiplication lights up photonic accelerator and beyond》(Zhou,Nature 2022)。这三种不同的方法分别是平面光转换(PLC)、马赫-曾德尔干涉仪(MZI)和波分复用(WDM)。
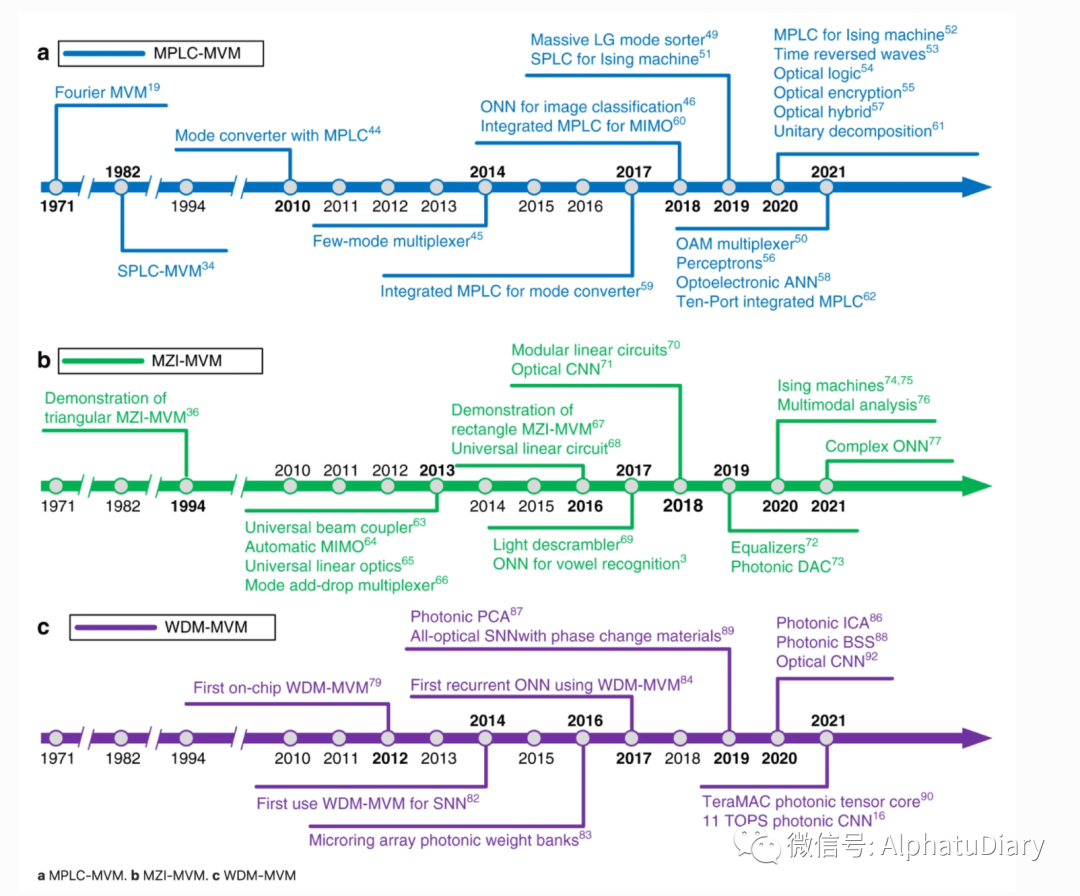
7. 提高agents的可用性
Agent指可以执行动作的大语言模型(可以理解为那些可以代替你来完成各种任务的代理人,所以叫Agent),例如浏览互联网、发送电子邮件、预订等。与本文中其他研究方向相比,这可能是最新的方向之一。由于Agent本身的新颖性和巨大潜力,人们对Agent充满热情。而Auto-GPT现在是Github上 标星数量排名第25的、最受欢迎的repo。GPT-Engineering是另一个受欢迎的repo。
尽管这个方向令人兴奋,但人们仍然对大语言模型是否足够可靠和高性能,以及能够被赋予行动的权力,存在疑虑。然而,已经出现了一个应用场景,即将Agent用于社会研究,例如著名的斯坦福实验,该实验显示一小簇生成式Agent产生了新兴的社会行为:例如,从一个用户指定的想法开始,一个Agent想要举办情人节派对,Agent在接下来的两天里自动传播派对的邀请,结交新朋友,互相邀请参加派对...(Generative Agents: Interactive Simulacra of Human Behavior, Park et al., 2023),
在这个领域最值得注意的创业公司也许是Adept,由两位前Transformer的合著者和前OpenAI副总裁创立,到目前为止已经融资近5亿美元。去年,他们展示了他们的agent的如何浏览互联网的,还有就是演示了如何向Salesforce添加新账户。
8. 迭代RLHF
RLHF(从人类反馈中进行强化学习)很酷,但有点技巧性。如果人们找到更好的训练LLM的方法,也不奇怪。不过,在RLHF方面还存在许多未解决的问题,例如:
①如何用数学方式,表示人类偏好?
目前,人类偏好是通过比较来确定的:人类标注员确定响应A是否比响应B更好。然而,它没有考虑响应A比响应B好多少。
②什么是人类偏好(preference)?
Anthropic根据输出,在有益、诚实和无害三个方面对其模型的质量进行了衡量。请参阅Constitutional AI: Harmlessness from AI Feedback (Bai et al., 2022).
DeepMind试图生成能够取悦大多数人的响应。请参阅Fine-tuning language models to find agreement among humans with diverse preferences, (Bakker et al., 2022).
此外,我们想要能够表达立场的AI,还是对任何可能具有争议性的话题回避的传统AI呢?
③“人类”偏好究竟是谁的偏好,是否要考虑到文化、宗教、政治倾向等的差异?获得足够代表所有潜在用户的训练数据存在许多挑战。
例如,对于OpenAI的InstructGPT数据,没有65岁以上的标注员。标注员主要是菲律宾人和孟加拉人。请参阅InstructGPT: Training language models to follow instructions with human feedback (Ouyang et al., 2022).

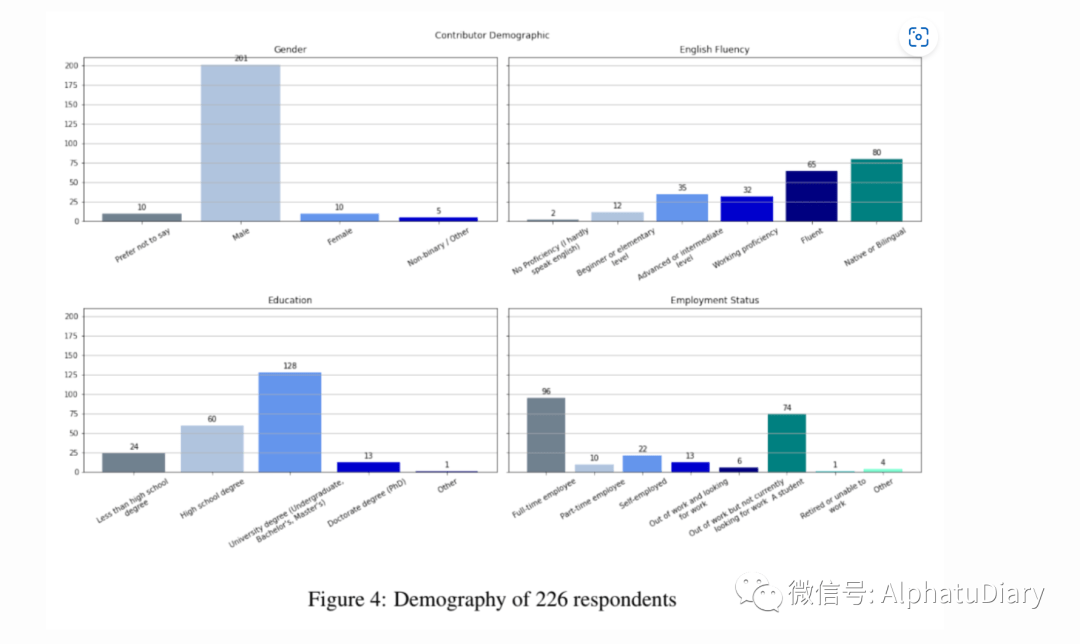
InstructGPT标注员的国籍统计信息
尽管社区主导的努力在其意图上值得赞赏,但可能导致数据存在偏见。例如,对于OpenAssistant数据集,222位(90.5%)回答者中有201位自我认定为男性。Jeremy Howard在Twitter上有一个很好的Thread:
9.提高聊天界面效率
自 ChatGPT 以来,人们一直在讨论聊天是否是一个适用于各种任务的界面。
详见:
Natural language is the lazy user interface(Austin Z. Henley, 2023)
Why Chatbots Are Not the Future(Amelia Wattenberger, 2023)
What Types of Questions Require Conversation to Answer? A Case Study of AskReddit Questions(Huang et al., 2023)
AI chat interfaces could become the primary user interface to read documentation(Tom Johnson, 2023)
Interacting with LLMs with Minimal Chat (Eugene Yan, 2023)
然而,这并不是一个新话题。在许多国家,尤其是在亚洲,聊天已经作为超级应用的界面使用了大约十年时间,Dan Grover在2014年就已经写过相关论文。

2016 年,当许多人认为应用程序已死、聊天机器人将成为未来时,讨论再次变得激烈紧张起来:
On chat as interface(Alistair Croll, 2016)
Is the Chatbot Trend One Big Misunderstanding?(Will Knight, 2016)
Bots won’t replace apps. Better apps will replace apps (Dan Grover, 2016)
我个人喜欢聊天界面,原因如下:
①聊天界面是每个人,甚至是没有先前接触过计算机或互联网的人,都可以迅速学会使用的界面(普适性)。在2010年代初,当我在肯尼亚的一个低收入居民区做志愿者时,我惊讶于那里的每个人在手机上进行银行业务时是多么熟悉,通过短信。那个社区没有人有计算机。
② 聊天界面是易于访问的。如果你的双手整忙于其他事情,可以使用语音而不是文本。
③ 聊天也是一个非常强大的界面--你可以向它提出任何请求,它都会给予回复,即使回复不一定完美
不过,笔者认为聊天界面在某些方面还可以继续改进:
①单次可交流多条消息
目前,我们基本上假设每次交流只有单轮消息。但这不是我和我的朋友发短信的方式。通常,我需要多条消息来完成我的思考,因为我需要插入不同的数据(例如图像、位置、链接),我可能在之前的消息中遗漏了某些内容,或者只是不想把所有内容都放在单一的大段落里。
②多模态输入
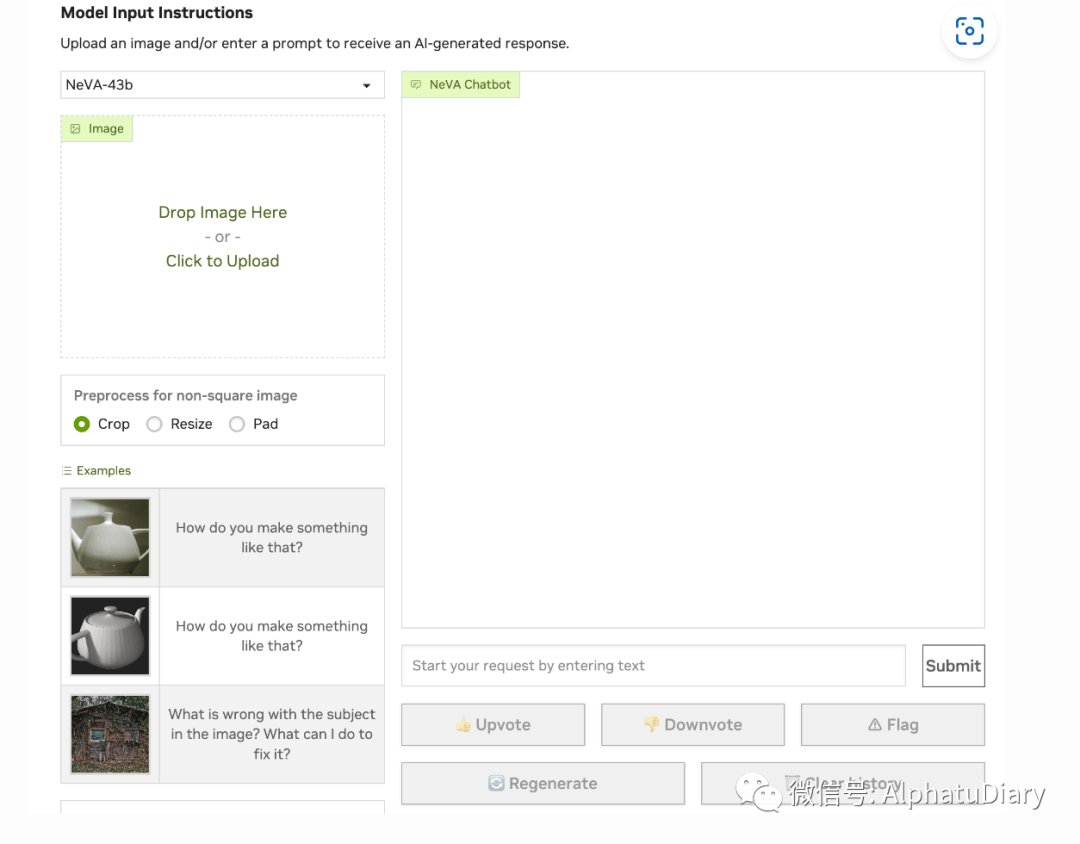
在多模态应用领域,大部分精力都花在构建更好的模型上,而很少花在构建更好的界面上。以Nvidia的NeVA聊天机器人为例。我不是用户体验专家,但我认为在这里可能有改进的空间。
附注:对这里提到NeVA团队表示抱歉,即使有了这个,你们的工作仍然非常酷!
③将生成式AI融入工作流程中
Linus Lee在他的分享“Generative AI interface beyond chats.”中很好地涵盖了这一点。例如,如果您想问关于您正在处理的图表中的某一列的问题,您应该能够只需指向那一列并提问。
④消息编辑和删除
用户输入的编辑或删除会如何改变与聊天机器人的对话流程?
10. 为非英语语言创建 LLM
我们知道,目前以英语为第一语言的 LLM 在性能、延迟和速度方面都无法很好地适用于许多其他语言。请参阅:
ChatGPT Beyond English: Towards a Comprehensive Evaluation of Large Language Models in Multilingual Learning(Lai et al., 2023)
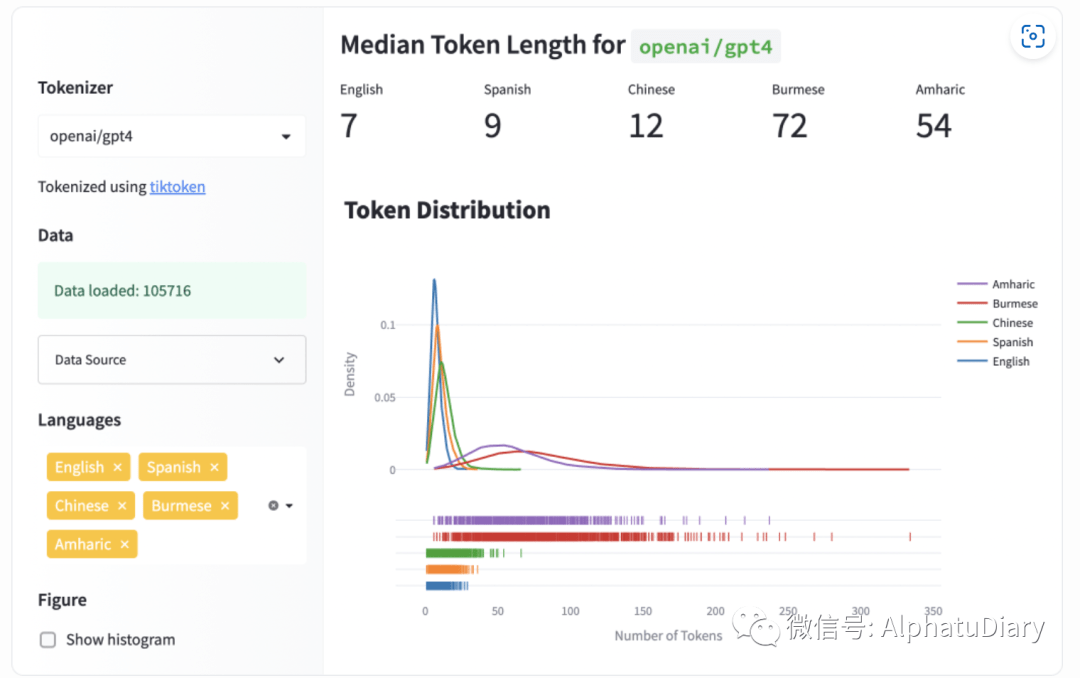
All languages are NOT created (tokenized) equal (Yennie Jun, 2023)
我只知道训练越南语的尝试(比如Symato 社区尝试),不过,本文几位早期读者告诉我,他们认为我不应该把这个方向包括进来,原因如下:
这与其说是一个研究问题,不如说是一个logistics问题。我们已经知道如何去做,只是需要有人投入资金和精力。不过,这并不完全正确。大多数语言都被认为是low-resource语言,例如,与英语或中文相比,很多语种的高质量数据要少得多,因此可能需要不同的技术来训练大型语言模型。参见:
Low-resource Languages: A Review of Past Work and Future Challenges(Magueresse et al., 2020)
JW300: A Wide-Coverage Parallel Corpus for Low-Resource Languages (Agić et al., 2019)
那些更为悲观的人认为,在未来,许多语言将会消失,互联网将由两个语言组成的两个宇宙:英语和汉语。这种思潮并不新鲜 - 有人还记得Esperanto吗?
人工智能工具,例如机器翻译和聊天机器人,对语言学习的影响仍然不明确。它们会帮助人们更快地学习新语言,还是会完全消除学习新语言的需求。
结论
本文如有任何遗漏,请告知我,为了获取其他观点,请查阅这篇全面的论文《Challenges and Applications of Large Language Models (Kaddour et al., 2023).
上述问题比其他问题更加困难。例如,我认为上述第10个问题,即建立非英语语言的 LLM,只要有足够的时间和资源,就会比较简单。
上述第 1 个问题是减少幻觉输出,这将会难得多,因为幻觉只是 LLM 在做概率的事情。
第 4 ,让 LLM 更快、更便宜,这一点永远无法彻底解决。这方面已经取得了很大进展,以后还会有更多进展,但是这个方向的改进将会一直持续。
第 5 项和第 6 项,即新架构和新硬件,非常具有挑战性,但随着时间的推移,它们是不可避免的。由于架构和硬件之间的共生关系——新架构需要针对通用硬件进行优化,而硬件需要支持通用架构,它们可能会由同一家公司来完成。
有些问题仅靠技术知识是无法解决的。例如,第 8 个问题,即改进从人类偏好中学习的方法,可能更多的是一个政策问题,而不是技术问题。第 9 个问题是提高聊天界面的效率,这更像是用户体验问题。我们需要更多具有非技术背景的人员与我们一起解决这些问题。
你最感兴趣的研究方向是什么?认为最有希望解决这些问题的方案是什么?很想听听您的意见。



























